
by Polina Yan
Starting an adult site that makes money comes down to a few steps. Pick a niche with real demand and choose a model like a paysite or webcam setup. Build the platform using adult-friendly hosting and proper payment tools. If you’re figuring out how to start a porn site, focus on traffic next. Use SEO, tube platforms, and communities to bring users in. Then convert them into paying customers through subscriptions, PPV content, tips, and private shows.
If you’re seriously thinking about how to start a porn site, let’s clear one thing up right away. This is not some overnight money trick. The adult industry makes huge money, yes, but most new sites never earn anything meaningful. Not because the niche is “too saturated,” but because people jump in without a plan.
They pick a random domain, upload a few videos, and expect traffic to magically turn into cash. It doesn’t work like that. This space is competitive, fast-moving, and surprisingly technical once you get past the surface.
At the same time, it’s still one of the few industries where a small, well-positioned project can grow into a real income stream. The key difference is approach. The sites that make money treat it like a business from day one. They choose a clear niche, build the right type of platform, and focus on monetization instead of just views.
This guide walks you through that process step by step, without fluff.
Why Porn Sites Still Make Money

A lot of people look at the adult industry and assume the gold rush is over. Too many free videos, too many giant brands, too much competition. That part is true. This market is crowded. It is also still very big, very active, and very capable of making money for operators who build around the right model instead of chasing empty traffic. Research and market reports place the global online adult entertainment market at about $81.9 billion in 2025, up from $76.2 billion in 2024. On the audience side, the scale is massive too: Reuters reported that Pornhub says it gets more than 100 million daily visits and 36 billion visits a year, while recent academic work also describes the Pornhub network as receiving over 100 million visits a day.
Traffic vs revenue — why free content dominates views
Free porn wins on reach because the internet is built for cheap access, fast clicks, and endless browsing. Tube sites trained users to sample first and commit later, if they commit at all. That is why so many new founders get stuck. They think traffic itself is the business. It is not. Traffic is only useful when there is a clear path from curiosity to payment. If you are figuring out how to start a porn site, this is one of the first hard truths to accept: millions of pageviews can still produce weak revenue if your monetization setup is flimsy. The free tube ecosystem gets huge attention because it offers convenience, volume, and constant novelty, but those same traits also make it hard for smaller sites to build loyalty or strong revenue per visitor.
That’s why chasing raw views can turn into a bad business habit. A site packed with free scenes may look busy, but unless it funnels people toward paid offers, live interaction, memberships, or premium access, it behaves more like an expensive storage bill with comments attached. The numbers can flatter you while the margins stay thin. Big free sites can survive on scale, ad relationships, and brand recognition. A smaller operator usually cannot.
Where actual money is made
The real money usually shows up where access is restricted, the experience feels personal, or the user has a reason to return. Subscription behavior is a strong example. Reuters reported that OnlyFans generated $6.6 billion in fan payments for the year ending November 2023 and keeps a 20% commission from creator earnings. That tells you something important about the market: users may browse free content all day, but they still pay when the offer feels exclusive, ongoing, or tied to a specific performer.
Live interaction is even stronger in some cases because it raises spending per user. Tips, private shows, custom requests, and direct fan attention create a completely different money pattern from passive video viewing. So when people ask about how to start a porn site, the better question is usually not “how do I get the most traffic?” but “what exactly will make a visitor pay?” That answer matters more than views, more than vanity metrics, and more than whatever the analytics dashboard is doing on a random Tuesday.
Step 1 — Choose Your Business Model

Before you register a domain or upload a single video, you need to decide what kind of business you’re actually building. This step is where most beginners go wrong. They jump straight into content without understanding how the site will make money. If you’re figuring out how to start a porn site, this decision shapes everything that comes next: your tech stack, your content strategy, your traffic sources, and your revenue.
There are three core models that dominate the adult space. Each one works, but they behave very differently in practice.
Tube sites (traffic-first model)
This is what most people imagine first. A site full of free videos, organized into categories, optimized for search, and designed to attract large amounts of traffic.
How it works:
- You publish free content at scale
- Users browse, watch, and leave
- Revenue comes mostly from ads or traffic resale
Key characteristics:
- Heavy reliance on SEO
- Requires constant uploads
- Strong competition from major platforms
Advantages:
- Lower barrier to entry
- Easier to get initial traffic
- Works well if you understand SEO deeply
Challenges:
- Revenue per user is very low
- Requires massive traffic to be profitable
- Competing with giants like tube networks is difficult
Reality check:
- A tube site is not a “passive” business
- It’s a content + SEO machine that needs constant input
This is often the worst starting point for beginners, even though it looks the easiest.
Paysites (subscription / PPV)
Paysites are built around restricted access. Users pay to unlock content, either through subscriptions or one-time purchases.
How it works:
- You gate content behind a paywall
- Users subscribe or buy individual videos
- Revenue comes directly from users
Key characteristics:
- Focus on content quality and identity
- Smaller audience, higher value per user
- Strong emphasis on retention
Advantages:
- Predictable recurring revenue
- Higher margins than ad-based models
- Full control over pricing and content
Challenges:
- Requires consistent content production
- Users expect exclusivity
- Harder to convert cold traffic
What makes it work:
- A clear niche
- Recognizable style or performers
- Regular updates that keep users subscribed
If someone asks how to make a porn site that actually earns without chasing millions of views, this model is usually a solid answer.
Webcam platforms (live monetization)
This model shifts everything toward real-time interaction. Instead of static content, users pay for attention, access, and direct engagement.
How it works:
- Performers stream live
- Users tip, pay for private shows, or request content
- Revenue is generated per session
Key characteristics:
- High spending per user
- Real-time engagement
- Strong performer-driven ecosystem
Advantages:
- Faster monetization
- Higher average revenue per user (ARPU)
- Strong user retention
Challenges:
- Requires performers or content creators
- Operational complexity is higher
- Needs stable infrastructure for streaming
Why it works:
- Users are not just consuming content
- They are interacting and influencing the experience
For many operators learning how to start a porn site, this model becomes the most profitable once it’s set up properly. Even with less traffic, the revenue can outperform both tube and traditional paysites.
Choosing the right direction
There is no “best” model in isolation. The right choice depends on what you can actually execute.
Quick way to decide:
- If you understand SEO and can produce volume → tube
- If you can create or manage premium content → paysite
- If you want faster revenue and direct monetization → webcam
The mistake is trying to mix everything too early. Pick one model, make it work, then expand.
Your business model is not just a format. It’s the engine that turns traffic into money. Get this wrong, and nothing else will save the project.
Model Comparison
| Factor | Porntube | Adult Paysite | Webcam |
| Revenue per user | Very low | Medium | High |
| Monetization speed | Slow | Medium | Fast |
| Traffic dependency | Very high | Medium | Low |
| Content volume | Massive | Moderate | Live |
| Tech complexity | Medium | Medium | High |
| ROI potential | Medium | High | Very High |
Step 2 — Choosing a Niche That Converts

The moment you decide to build “just a porn site,” you’ve already made it harder for yourself. That idea sounds big, but it’s actually empty. It doesn’t tell anyone what they’re getting, and it doesn’t give you a way to stand out.
People don’t search for “porn” and stop there. They look for something specific. A type of body, a certain dynamic, a mood, a scenario. Sometimes it’s obvious, sometimes it’s weirdly specific, but it’s always narrower than you think. If you ignore that and try to cover everything, your site ends up looking like a weaker version of something that already exists.
If you’re serious about how to start a porn site, the niche isn’t a detail. It’s the whole foundation.
Why niche beats “general porn”
Think about how people actually consume this content. They click around, sure, but once something hits the right nerve, they stay there. They watch more from the same creator, the same category, the same vibe. That’s where money starts to show up.
From an SEO side, it’s even more brutal. Broad keywords are locked down by massive platforms. You’re not sneaking past them with a fresh domain and a few uploads. But a focused niche gives you space. You can build pages around specific searches, stack content that actually relates to each other, and slowly build visibility instead of shouting into a void.
More importantly, a niche makes your site feel intentional. Without it, everything looks random. With it, even simple content starts to feel like part of something.
How to validate a niche
Before you go all in, you need a quick reality check. Not a spreadsheet, just basic signals that this idea isn’t dead on arrival.
Start by looking at search and browsing behavior. Are people actively looking for this kind of content, or does it only exist in your head? Then check how it behaves on tube platforms. If clips in that category get consistent views and comments, that’s already a good sign.
Next question is more important: do people pay here?
Some niches get tons of views but almost no conversions. Others look smaller but have users who spend money without hesitation. That difference matters more than raw traffic. If you’re working out how to create a porn site, you’re not building for views. You’re building for transactions.
Competition is the third filter. If every result looks like a polished studio with huge budgets, you’ll struggle. If you see a mix of mid-level sites and independent creators, that’s usually where opportunities live.
What niches actually convert
You’ll notice a pattern once you look at what works. It’s rarely about being the biggest or the most polished. It’s about being specific enough that the user feels like this is exactly what they were looking for.
- Amateur content keeps performing because it feels closer to real life. It doesn’t try too hard, and that’s the point
- Fetish niches go deep instead of wide. The audience is smaller, but far more loyal and willing to spend
- Creator-driven formats work because people attach to personalities, not just videos
- Live models turn everything into interaction, and once users start engaging, they spend differently
The common thread is simple. The more replaceable your content is, the harder it is to make money. The more specific and recognizable it becomes, the easier it is to convert.
Step 3 — Domain + Hosting

At this stage, things stop being abstract and start getting practical. You’re no longer thinking about ideas, you’re making decisions that can either support your site or quietly break it later. If you’re figuring out how to start a porn site, this is where many beginners get blindsided. They assume hosting is just “buy a server and upload videos.” In the adult industry, it’s never that simple.
Domain strategy for adult projects
Let’s start with the domain. It sounds like a small detail, but it shapes how people remember you and how search engines understand your site.
First mistake people make is going too generic or too explicit. Something like “bestfreehardcorevideos.xxx” might feel SEO-friendly, but it’s forgettable and looks cheap. On the other hand, overly clever brand names that hide the niche completely make it harder for users to understand what they’re clicking on.
A better approach is balance:
- Keep it readable and short
- Hint at the niche without stuffing keywords
- Make sure it doesn’t look like spam
When it comes to registrars, you also need to be careful. Not every provider is comfortable with adult content, even if they don’t say it upfront. That’s why many operators stick to well-known, flexible registrars that don’t interfere with content type.
A few commonly used options:
- Namecheap is popular because it’s affordable and generally tolerant of adult domains, making it a safe default for smaller projects.
- Njalla is often chosen when privacy matters more, since it offers stronger anonymity, but it’s less beginner-friendly.
- Epik has historically been used in controversial or restricted niches, though its reputation and policies have shifted over time, so it requires extra caution.
The domain itself won’t make you money, but a bad one can quietly limit your growth.
Hosting reality
Hosting is where things get serious. Adult content is still treated as high-risk by many providers, even in 2026. You can get approved, launch your site, and still get suspended later if your host decides you’re not worth the trouble.
This is why “adult-friendly” hosting isn’t optional. It’s a requirement.
A few providers that are often used in this space:
- ViceTemple focuses specifically on adult hosting and offers servers optimized for video-heavy websites, which makes it a common choice for new and mid-sized projects.
- Hostwinds is more general-purpose, but allows adult content and gives you flexible VPS options if you need to scale gradually instead of committing upfront.
- BlueAngelHost is known for offshore hosting, which some operators choose for additional flexibility around content policies, though it comes with trade-offs in latency and support.
- AbeloHost is another offshore option with strong privacy positioning, often used when operators want to minimize regulatory exposure.
When choosing hosting, focus on what actually matters:
- Bandwidth matters more than storage. Video traffic eats resources fast, and underestimating this is one of the quickest ways to break your site under load.
- Stability matters more than price. Cheap hosting looks attractive until your site goes down during peak traffic or gets throttled.
- Policy clarity matters more than promises. If the provider is vague about adult content, assume problems later.
There’s also a hidden risk many people ignore. Even if your host allows adult content, they can still shut you down if your traffic spikes too fast, your content triggers complaints, or your payment processing raises flags.
If you’re learning how to start a porn site, think of hosting as infrastructure, not a checkbox. It’s the thing that quietly determines whether your site survives growth or collapses the moment things start working.
Step 4 — Platform: CMS vs Custom Build
At this point, the question is no longer “can I launch a site,” but “how far can this setup take me before it breaks.” The platform choice looks technical on the surface, but it directly affects how you make money, how stable the site is, and how painful future upgrades become.
WordPress and quick setups
WordPress is the fastest way to get something running, especially in adult where prebuilt themes already cover a lot of ground. You don’t start from zero. You install a theme, configure categories, upload content, and you’re live.
There are several adult-focused themes that are commonly used:
- MyTubePress is built specifically for tube-style sites. It focuses on video aggregation, auto-importing content, and structuring large libraries. This makes it attractive if you’re trying to scale content quickly, but it also pushes you toward a traffic-heavy model.
- AdultXTheme leans more toward premium layouts and monetized content. It supports paywalls and membership-style structures, which makes it more suitable for paysites rather than free tube clones.
- BangThemes is a broader category of adult WordPress templates designed for different formats, including tubes, galleries, and hybrid sites. These are often used for quick launches where design and layout matter more than backend flexibility.
These tools save time, no question. You can go from idea to working site in a day or two.
But the trade-offs show up fast:
- Monetization becomes limited once you need more than basic subscriptions or simple paywalls. You end up forcing business logic through plugins that were never designed for adult use cases.
- Performance degrades as content grows, especially with video-heavy pages. Optimization turns into a constant task rather than a one-time setup.
- You are dependent on theme updates and plugin compatibility, which can break parts of your site unexpectedly.
WordPress works well for testing ideas. It struggles when the project starts behaving like a real business.
Custom platforms and scalability
Custom development flips the approach. Instead of adjusting your idea to fit a theme, you build the system around how your business actually operates.
That becomes critical the moment monetization gets serious.
- You can implement subscriptions, PPV, tipping, or private sessions exactly the way you want, instead of adapting to plugin limitations.
- Performance can be tuned for video delivery and user behavior, which keeps the site stable under load.
- You control user data, pricing logic, and access rules without relying on external systems that can change or restrict you.
Another difference appears over time. Adding new features to a custom platform feels like extending a system. Doing the same on top of a patched CMS setup often feels like stacking temporary fixes.
For anyone digging into how to start a porn site, this is where the long-term thinking kicks in. The question shifts from “what’s the fastest way to launch” to “what won’t collapse when it starts working.”
Platform Decision
| Feature | Builders like WordPress | Custom Development |
| Setup speed | Fast | Slow |
| Monetization | Limited | Full |
| Scalability | Weak | Strong |
| Ownership | Partial | Full |
Step 5 — Content Strategy

Content is where most projects either start making money or quietly die. Not because people don’t upload enough videos, but because they misunderstand what actually keeps users engaged and willing to pay. Views alone don’t mean much here. What matters is whether someone stays, comes back, and eventually spends.
What content converts
There’s a difference between content that gets clicks and content that generates revenue. The second one usually feels more specific, more personal, and less replaceable.
Video is still the core format, but not all videos behave the same. Highly polished studio scenes can work, but they’re also the easiest to replace. Amateur-style content, on the other hand, often performs better because it feels more real. The viewer isn’t just watching a scene, they’re buying into a situation.
Live content takes this even further. The moment interaction enters the picture, the whole dynamic changes. Users stop being passive and start participating. That’s when tips, private shows, and custom requests appear. If you’re exploring how to start a porn site, this is the point where content stops being just media and becomes a service.
Authenticity plays a bigger role than people expect. Perfect lighting and editing are nice, but they don’t guarantee engagement. A consistent style, recognizable personalities, and a clear tone matter more over time.
Content production reality
This is the part most beginners underestimate. You don’t need to produce cinematic scenes, but you do need to show up regularly. Gaps in content kill momentum faster than low production quality.
A simple rule that works in practice:
- Upload consistently, even if the content is simple, because regular updates train users to return and signal activity to search engines and platforms.
- Distribute content instead of keeping it isolated, using short clips or previews on tube platforms and communities to bring users back to your main site.
- Focus on formats you can sustain long-term, because burning out after a few weeks is more damaging than starting small and growing steadily.
Consistency builds familiarity. Familiarity builds trust. And trust is what eventually turns a casual viewer into someone who pays.
At some point, content stops being random uploads and becomes a system. That’s when things start to work.
Step 6 — Traffic Strategy
Traffic is where most plans collapse. You can have a solid niche and decent content, but without distribution, nothing moves. This is the part people underestimate when thinking about how to start a porn site, because it’s less about building and more about getting seen.
SEO and search traffic
Search traffic is slow, but it compounds. You’re not chasing one viral hit. You’re stacking pages that answer specific queries, even if they’re low volume.
Structure matters more than people think:
- categories should reflect real search behavior
- tags shouldn’t be random, they should group similar intent
- pages need to connect logically so users don’t bounce after one click
For adult websites, SEO isn’t just important, it’s the lifeblood of their marketing. Mainstream advertising platforms like Google Ads and Facebook strictly ban or restrict explicit adult content, cutting off the paid acquisition channels most other industries rely on. This makes ranking high in organic search one of the only reliable ways for adult sites to connect with their audience.
— Rank AI, Adult SEO 2025: Complete Guide to Rank, Links & Traffic
It takes time, but once it starts working, it becomes one of the most stable traffic sources. That’s why anyone serious about how to start a porn site and make money eventually leans into SEO, even if it’s not exciting at the beginning.
Tube platforms as funnels
Tube sites are not your competition at the start. They’re your distribution layer.
You don’t upload full content there. You upload clips:
- short previews
- cut scenes
- highlights
The goal is simple: clip → curiosity → click → your site.
This is one of the few reliable ways to tap into existing traffic instead of trying to build it from zero. It also works well alongside affiliate programs, where traffic can be routed not only to your own content but also to partner offers that generate commission.
Communities and distribution
Communities are less predictable, but often more engaged. Reddit, niche forums, and smaller content hubs can drive highly targeted traffic if you approach them correctly.
What works here:
- posting content that fits the community instead of spamming links
- building a presence before pushing traffic
- understanding the tone of each space
People in these communities are not just browsing. They’re discussing, recommending, and reacting. That makes them more likely to click through and convert if the content matches what they expect.
Traffic is not one channel. It’s a mix. The sites that grow are the ones that combine search, platforms, and communities instead of relying on a single source.
Step 7 — Monetization
This is the part everyone cares about, but also the part most people misunderstand. Traffic alone doesn’t pay anything. You need clear ways to turn attention into money, and that usually means combining several revenue streams instead of relying on just one. When people look into how to start a porn site, they often focus on getting visitors first and only think about monetization later. That’s backwards. The money model should be clear from day one.
The core revenue streams are simple:
- Subscriptions give you recurring income, especially if your content updates regularly and feels worth coming back to.
- Pay-per-view (PPV) works well for premium scenes or exclusive content that users can’t access anywhere else.
- Tips create spontaneous income, especially when there is some form of interaction or personal connection.
- Private shows or custom content generate the highest payouts because users are paying for direct attention.
Each of these works differently, but the real strength comes from combining them. A user might subscribe, then buy a premium video, then tip during a live session. That layered behavior is where revenue starts scaling.
Now the numbers:
- Visitors per month: 12,000
- Conversion rate: 2%
- Paying users: 12,000 × 0.02 = 240
- Subscription price: $18
Revenue: 240 × $18 = $4,320/month
This is just the base layer. Once additional purchases like PPV content or private interactions are added, the total revenue per user increases, often significantly.
Step 8 — Payments + Legal
This is where a lot of otherwise decent projects get shut down. Not because of bad content, but because payments fail or compliance is ignored. In this niche, money flow is fragile by default. While figuring out how to start a porn site, most people underestimate how strict this layer actually is.
Payment systems
Adult businesses are classified as high-risk. That changes everything. Banks are cautious, mainstream processors often refuse service, and even approved accounts can be frozen.
You’ll need providers that specialize in this space. Common options include CCBill, Epoch, Segpay, Corepay, and PayKings. These are built specifically for adult subscriptions, webcam platforms, and content-based services. They handle recurring billing, fraud protection, and chargebacks better than general-purpose processors.
Fees are higher too. It’s normal to see increased transaction rates because of higher chargeback risk and stricter underwriting.
And there’s one hard rule: platforms like PayPal or Stripe will not reliably support explicit adult content. Trying to “sneak through” usually ends with frozen funds.
Legal basics
Legal isn’t optional here. In the adult space, compliance directly affects whether your site can operate, process payments, and stay online.
18 U.S.C. § 2257 (USA) requires strict record-keeping to prove that all performers are adults. This includes IDs, consent forms, and documentation tied to every piece of content.
Regulation is getting stricter, not lighter. In the EU, the Digital Services Act (DSA) increases responsibility for platforms hosting user-generated content, including faster takedown requirements and stronger oversight. In the UK, the Online Safety Act pushes mandatory age verification for users accessing adult content, with real enforcement and penalties.
Age verification is no longer just about performers. In many regions, platforms are expected to verify users as well, especially when explicit material is involved.
GDPR (EU) applies if you collect user data, meaning you must handle personal information, payments, and tracking responsibly.
Content ownership and consent must be documented. If someone appears in your content without proper release forms, that becomes a legal risk immediately.
Payment processors are tightly connected to compliance. If your documentation, verification, or content policies don’t meet their standards, they will shut down your account before regulators even step in.
Case Studies

Looking at real platforms makes things clearer than any theory. Each of these businesses earns money in a completely different way, even though they all operate in the same industry.
Subscription model — OnlyFans
OnlyFans is the clearest example of subscription-driven revenue. The platform processed around $6.6 billion in user spending, taking a 20% cut from creators. The key here is not just content, but the relationship. Users subscribe to people, not categories. That’s why creators with strong identities outperform those who rely only on explicit content.
Tube traffic model — Pornhub
Pornhub represents the opposite approach. It dominates through scale, offering free content and generating revenue through ads, partnerships, and traffic distribution. The numbers are massive, but so is the competition. This model works best when you can operate at scale or plug into existing traffic ecosystems.
Webcam monetization — Chaturbate
Chaturbate shows how live interaction changes spending behavior. Instead of passive viewing, users pay for attention, control, and real-time engagement. Tips, private shows, and custom interactions push revenue per user much higher than traditional video models.
Hybrid model — ManyVids
ManyVids blends several approaches. Creators sell clips, offer custom content, run fan clubs, and receive tips. This layered structure increases lifetime value because users can spend in multiple ways instead of just one.
The pattern is simple. Each model earns differently, and success depends on choosing one that fits your resources and goals. That’s exactly why many operators move toward building their own platforms instead of relying entirely on third-party ecosystems.
Create a Webcam or Paysite with Scrile Stream
At some point, using third-party platforms starts to feel limiting. You don’t control pricing, you don’t own the audience, and one policy change can cut your revenue overnight. That’s where building your own solution starts to make sense.
Scrile Stream is not a ready-made platform. It’s a development service that helps you launch a custom adult site built around your business model. Whether you’re focusing on live webcam interaction or a premium paysite, the idea is simple: you get infrastructure designed for monetization from the start.
What this changes in practice:
- You can launch a webcam setup with built-in features like private shows, tipping systems, and real-time interaction instead of trying to patch these things together later.
- Payments go directly through your own system, which means you’re not sharing revenue with a platform that controls access to your users.
- The product can be shaped around your niche, your performers, and your monetization logic instead of fitting into a predefined template.
Ownership is the biggest shift. You control user data, pricing, access rules, and growth strategy. That’s a different position compared to building on top of marketplaces where the audience never truly belongs to you.
For anyone exploring how to start a porn site as a long-term business, this approach makes more sense once you move beyond testing ideas. It’s not the fastest way to launch, but it’s one of the few ways to build something that can scale without hitting platform limits.
What Should You Choose?
| Situation | Best Choice | Why It Works | Main Trade-Off |
| Fast money | Webcam | Direct interaction drives tips, private shows, and high spend per user | Requires performers and live moderation |
| Stable income | Paysite | Recurring subscriptions create predictable monthly revenue | Needs consistent content updates |
| SEO scaling | Tube | Large content libraries can attract steady organic traffic over time | Low revenue per user, heavy competition |
| Brand building | Paysite | Strong identity and niche positioning help build loyal audience | Slower growth at the start |
| High revenue potential | Webcam | High ARPU through real-time engagement and upsells | More complex to operate and scale |
Conclusion
This isn’t a side project. It’s a real adult site business where profit depends on how well you align your model, niche, and traffic. The difference between an adult site that earns and one that goes nowhere comes down to execution, not ideas or luck. If you’re serious about how to start a porn site, you need to treat it like a structured system from day one.
If you want to build a scalable adult site with real monetization instead of relying on third-party platforms, contact the Scrile Stream team and launch your project the right way.
FAQ
How much does it cost to start an adult site?
A small launch can start with a modest budget if you use simple tools, but a serious adult site with custom features, streaming, and payments costs much more. The final number depends on your model, content plan, and tech stack.
Is it legal to run a porn site?
Yes, but only if you follow the laws in your target markets. That usually means age verification, consent records, performer documentation, and proper handling of user data.
What is the best niche for a new porn business?
Usually, a focused niche works better than broad generic porn. Amateur, fetish, creator-driven content, and live cam formats often convert better because they attract a more specific audience.
What is the best business model for beginners?
A paysite or webcam model is usually easier to monetize than a free tube site. Tube traffic can be huge, but it often takes longer to turn into real revenue.
How do porn sites get traffic in the beginning?
Most new projects use a mix of SEO, tube clips, communities, and affiliate traffic. Organic search helps over time, but distribution usually starts before rankings do.
How to start a porn site without relying only on ads?
Build around direct monetization instead of hoping banners will carry the business. Subscriptions, PPV, tips, private shows, and custom content usually bring better margins.
Which payment gateways work for adult sites?
Adult businesses usually need high-risk payment providers such as CCBill, Epoch, or Segpay. Mainstream processors often have stricter rules or may not support explicit content at all.
Should I use WordPress or build a custom adult platform?
WordPress is faster for testing an idea, but custom development gives you more control over monetization, ownership, and scaling. The right choice depends on whether you want a quick launch or a long-term business.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
Imagine this: Your inbox is overflowing, chat notifications are piling up, and you’re still staring at the blinking cursor, wondering how to craft the perfect response. Now, picture an AI response generator that instantly transforms your raw thoughts into polished messages—for emails, chats, or any text-based communication.
AI response generators are not all about convenience. They are powerful tools that help businesses maintain their brand voice, speed up customer support, and turn everyday communication into a breeze for individuals. Whether you are handling business emails or juggling multiple chat conversations, these AI generators can be a game-changer in 2025.
In this article, we will look at the top AI response generators, with a focus on those that perform best in chat, email, and text applications. Get ready to discover how the right AI text response generator can streamline your workflow and elevate your communication.
What is an AI Response Generator?

An AI response generator is a smart tool designed to create quick, relevant, and context-aware replies for emails, chat messages, and other text-based communications. Think of it as a virtual assistant that doesn’t just autocomplete your thoughts but crafts entire responses, saving you time and mental energy.
These technologies work by looking at your input—a customer inquiry, an internal email, or just a plain text message—and generating a response based on advanced algorithms and machine learning algorithms. They draw on vast language pattern libraries and previous interactions to create responses not only accurate but also in tone and context you desire.
From AI chat response generators to enhance customer service chatbots to AI email response generators that compose professional emails in seconds, the uses are varied. Whether you are a company seeking to boost efficiency or an individual seeking to automate everyday communication, AI text response generators can be a game-changer for productivity.
The Benefits of Using AI Response Generators
An AI response generator can significantly boost productivity by removing guesswork in communication. Instead of spending valuable time composing emails, responding to chat messages, or typing text responses, individuals and businesses can utilize AI tools to generate professional, context-based, and relevant responses in seconds.
For companies, the benefits are clear. Imagine a customer service department using an AI chat response generator that offers appropriate replies instantly. Not only does it accelerate replies, but it also encourages response consistency. A case study illustrated a company increasing customer support effectiveness by 30% when it implemented an AI text reply generator. The AI handled repetitive questions, allowing human representatives to work on more challenging issues.
At a personal level, an AI email response generator can help deal with full inboxes, with smart recommendations making it faster and easier to reply to emails. For business or private use, text response generators offer the perfect mix of speed, precision, and simplicity, and introduce communication into everyday life rather than a hassle.
How to Choose the Best AI Response Generator
When you select an AI response generator, it’s not necessarily about getting something that spews up text. It’s about getting a solution that actually works for your workflow and communications. The proper solution can comfortably handle everything from instant chat responses to crafting beautiful email responses. Here’s what to search for:
- Accuracy. The generator should create context-specific and appropriate responses. Advanced tools utilize natural language processing (NLP) to understand not just words, but the meaning of words. This ensures that whether you’re using an AI chat response generator or an email response generator, the replies make sense and align with your messaging.
- Customization. It is critical aspect, as each brand or person has a unique voice. A good AI text response generator should allow for tone, style, and even vocabulary changes. For companies, this feature is critical to maintain brand consistency on all platforms.
- Integration. The best tools are not isolated; they integrate perfectly with your current tech stack. Whether you need an AI email response generator that works with Gmail or a message response generator for your CRM, the integration features add much value to the AI.
- Ease of Use. Sophisticated AI is great, but it shouldn’t require a PhD to operate. The interface should be intuitive, offering features like one-click response generation and the ability to tweak outputs quickly.
- Affordability. Whether you’re an enterprise with a large budget or an individual looking for a free tool, the cost-to-benefit ratio matters. Usage-based scalable pricing is offered in some tools, which can be a perfect option for growing businesses.
Tips for Different Users:
- Businesses. Look for analytics, response templates, and multi-user capabilities. These can help increase productivity, allow monitoring of communication metrics, and offer consistency across the company.
- Individuals. If you’re focused on personal productivity, a lightweight text response generator with pre-made suggestions and a straightforward interface might be ideal.
By weighing these factors carefully, you’ll find an AI response tool that not only meets but exceeds your expectations, making your communication smoother, faster, and more effective.
Top 7 AI Response Generator Tools in 2025: The Best of the Best
When it comes to AI response generators, the market is brimming with tools that promise to streamline your communication. But not all are created equal. Here’s a look at some of the best options available in 2025, offering everything from smart chat replies to polished email responses.
| Tool | Best For | Key Strengths | Limitations |
|---|
| ChatGPT (OpenAI) | Cross-platform use, business & personal | Human-like replies, adaptable tone, email & chat integration | Subscription needed for advanced features |
| Jasper AI | Marketing & branded messaging | Strong brand voice control, CRM/email integrations | Better for content teams than casual users |
| Writesonic | Creative & contextual replies | Witty, tone-aware responses for social & email | May require fine-tuning for formal comms |
| Scrile AI (Custom) | Businesses needing tailored tools | Fully customized style, evolving with brand, monetization-ready | Requires custom setup, not plug-and-play |
| Zoho Desk | Customer support teams | Strong integrations with Zoho suite, auto-learns from past chats | Primarily for support, less flexible elsewhere |
| Drift AI | Sales & lead generation | Conversational marketing, proactive engagement | Focused on sales rather than general use |
| Tidio AI | Small businesses & e-commerce | Simple chatbot, Shopify/WordPress ready, affordable | Limited customization & depth |
ChatGPT by OpenAI
ChatGPT is a name that has become synonymous for a reason. Powered by OpenAI’s advanced GPT-4 architecture, this is no run-of-the-mill chatbot. It can do more than just have a casual conversation. It is especially adept at writing email replies, creating social media updates, and even assisting with creative writing. ChatGPT offers a cross-platform AI chat response generator that can seamlessly integrate into various platforms, from business communication software to personal messaging apps.
Businesses typically use ChatGPT to provide automated customer support. Imagine this: immediate replies to customer inquiries, 24/7, in human-sounding responses. This application of AI reduces wait times and increases customer satisfaction. For personal use, it can help you write well-thought-out emails or provide instant replies when you’re away from your desk. The app’s ability to adapt its tone and style based on context makes it a leading contender in the AI response market.
Jasper AI
Jasper AI has held its own, particularly in content creation and marketing. While it’s perhaps most well-known for creating lengthy content, Jasper is also a great AI text response generator. That it can maintain a brand voice and create consistent messaging makes it a favorite among businesses that need fast turnaround on messaging.
Jasper AI is particularly useful for drafting email responses. For example, if a business receives repetitive queries, Jasper can generate personalized replies that save time while keeping the tone professional. The tool’s customization features allow users to fine-tune responses, which is crucial for maintaining brand identity. Jasper also supports integration with CRM and email platforms, adding a layer of convenience for business users.
Writesonic
For those who need a message response generator that blends creativity with practicality, Writesonic is a solid pick. It is designed to generate everything from witty social media replies to formal email responses. It has an exceptional ability to generate contextually relevant replies, allowing businesses to engage more deeply with their audience.
Perhaps the most impressive feature of Writesonic is its commitment to understanding user intent. Whether you’re responding to a customer complaint or writing a promotional message, Writesonic carefully examines the tone of your message and generates a response that is perfectly suited to the right tone.
Scrile AI Response Generator Solutions
Scrile offers a unique approach to AI-generated responses by providing fully customizable solutions. Unlike other tools that offer generic automation, Scrile collaborates with businesses to create AI response generators tailored to specific needs. This could mean anything from a text response generator for customer service to a bespoke AI email response generator for sales teams.
What sets Scrile apart is its adaptability. The AI doesn’t just generate responses—it learns and evolves with your brand. For instance, a business can set specific guidelines for tone and style, ensuring every message aligns perfectly with brand values. Scrile’s solution is particularly beneficial for companies needing more than just a cookie-cutter response tool. It offers a partnership approach, where businesses and Scrile’s team work together to build a system that feels like a natural extension of the brand’s voice.
Zoho Desk
Zoho Desk is a brand that is popular in customer support, and its AI chat response generator is one of the reasons it has been successful. The software is designed to integrate easily with customer support procedures, giving auto-responses that enhance efficiency and consistency. Organizations can automate routine questions, allowing human representatives to deal with more complex issues.
One of the most useful things about Zoho Desk is how well it is integrated with other Zoho tools and third-party tools, so it is a great solution for businesses that already have Zoho’s suite of tools. The AI not only generates responses but also learns from past conversations to improve accuracy over time. This is a great solution for businesses that want to build a smarter, more effective customer support system.
Drift AI
Drift AI is carefully designed for the sales and customer interaction spaces. Its AI response generator is used to help companies reach out to potential customers through chatbots and automated emails. Not a simple automation tool, Drift’s AI uses conversational marketing strategies to create leads and boost conversion rates.
For example, when a prospect comes to a website, Drift AI can initiate a conversation, provide relevant information, and guide the prospect toward a purchase. As a virtual sales assistant, it helps businesses capitalize on every chance to connect with their audience. This proactive approach sets Drift apart, particularly for businesses with a strong focus on sales-driven communication.
Tidio AI
Tidio AI is an excellent choice for small businesses that need an affordable but effective text response solution. The software is primarily chatbot-based, and that is why it is perfect for businesses that need to respond to simple customer queries without a support team.
Tidio has a very simple setup process with seamless integration with popular e-commerce platforms like Shopify and WordPress. It enables businesses to provide instant responses to customer inquiries, significantly enhancing customer experience and driving sales. While it is not as customizable as some of its competitors, its ease of use and low price make it a good option for small businesses and start-ups.
Why Scrile’s AI Response Generator Stands Out
When it comes to AI response generators, Scrile takes a unique approach that goes far beyond standard automation. Instead of offering a one-size-fits-all solution, Scrile specializes in creating custom-built AI tools that match the specific communication style and needs of your business. Whether your goal is to automate customer service responses, improve sales conversations, or facilitate internal messaging, Scrile presents solutions that genuinely reflect the character of your company’s voice.
Perhaps the most impressive thing about Scrile’s AI solutions is their focus on going beyond simple automation. While other AI response generators can only generate boilerplate responses, Scrile’s technology is designed to understand the context and nuance of each conversation. As a result, your messages not only eschew the stiff tone that automation is so often criticized for—they have a personal and thoughtful feel, so that every response captures your business’s tone and values.
Scrile’s real-world adaptability is another major advantage. Unlike many static tools, Scrile’s AI evolves alongside your business. Each update or added feature enhances its response quality, keeping your communication strategies fresh and relevant. It’s like having an AI that learns and improves with every interaction, offering a dynamic experience rather than a fixed set of responses.
What truly sets Scrile apart is its personalized collaboration approach. Instead of simply providing a tool and walking away, Scrile works closely with businesses to develop AI solutions that fit like a glove. This partnership ensures that the response generator isn’t just an off-the-shelf product but a carefully crafted extension of your brand’s communication strategy.
If you’re looking for an AI text response generator that offers more than just automated replies, Scrile’s solution is worth exploring. It transforms AI-driven interactions from robotic to dynamic, providing a real competitive edge in today’s fast-paced digital landscape.
Generic Response Generators vs. Scrile AI
| Option | Voice & Branding | Adaptability | Integration | Best Fit |
|---|
| Generic Tools (ChatGPT, Jasper, etc.) | Fixed templates & tones | Limited evolution beyond updates | Broad but shallow integrations | Individuals & SMBs |
| Scrile AI (Custom Build) | Fully aligned with your brand | Learns & evolves with each interaction | Custom integrations (CRM, sales, support) | Businesses & platforms |
Conclusion
Selecting the right AI response generator can make a significant difference in productivity, communication efficiency, and brand consistency. With so many tools at your disposal, you need to pick a solution that not only provides automatic responses but also adapts to your specific needs, whether for chat, email, or overall text communication.
Of the contenders being considered, Scrile stands out as a top choice. Unlike traditional tools, Scrile offers customized AI solutions that reflect your brand’s voice and evolve as your business expands. It goes beyond simple automation; it is about creating genuine interactions that appeal to both humanity and thoughtfulness.
Are you ready to take your communication to the next level? Explore how Scrile’s AI response generator can help you save time, maintain a professional tone, and improve your interactions with customers. Discover the many ways Scrile can transform your business’s communication strategy, adding a lively and personalized touch to every message.
FAQ – AI Response Generator (Email, Chat, Support, Brand Voice)
Practical answers for choosing and using AI response generators in 2025–2026: accuracy, tone control, integrations, privacy, and when a custom solution makes more sense.
What is an AI response generator?
▾
An AI response generator is a tool that drafts context-aware replies for emails, chats, and messages. Instead of only suggesting words, it generates full responses that you can edit and send.
The best ones don’t just “write fast.” They keep your tone consistent, reduce overthinking, and help teams reply at scale without sounding robotic.
AI response generator vs chatbot: what’s the difference?
▾
A response generator helps a human reply faster (suggested drafts you approve). A chatbot tries to reply automatically to users without a human in the loop.
If you need quality control and brand safety, response generators are often the safer first step. Full automation makes sense later—after you’ve validated tone rules, edge cases, and escalation paths.
When should I use an AI email response generator vs templates?
▾
Templates are perfect for standard replies that rarely change. AI becomes valuable when context matters: a customer complaint, a nuanced negotiation, or a message that needs empathy and personalization.
A practical workflow is “template + AI polish.” Keep your structure, then let AI adapt wording, tone, and length to each specific message.
How do I make AI replies match my brand voice?
▾
Give the AI clear rules: tone (friendly / formal), length, words to avoid, and examples of “good replies.” This is better than vague instructions like “sound professional.”
If you’re a team, create a small “voice guide” with 5–10 sample replies. Consistency comes from constraints, not from hoping the model guesses your style.
What integrations should I look for (Gmail, helpdesk, CRM, live chat)?
▾
Pick integrations that remove copy-paste. For email teams: Gmail/Outlook. For support: helpdesk tools, ticket context, macros, and tags. For sales: CRM fields and pipeline stages.
The best AI replies are “context-fed.” If the tool can see order status, plan type, and past messages (with proper permissions), the drafts become faster and more accurate.
How do I prevent wrong answers and “confident nonsense” in replies?
▾
Treat AI drafts as suggestions, not truth. For anything factual (pricing, policies, refunds, legal terms), require the reply to reference your internal source (FAQ, docs, CRM fields) before sending.
Build a rule: if the AI isn’t sure, it should ask a clarifying question or escalate. This single constraint reduces risky replies dramatically.
Is it safe to paste customer messages into an AI response generator?
▾
It can be, but only if you treat privacy as a product requirement. Avoid sending secrets, passwords, payment details, or anything you wouldn’t want stored or logged.
For businesses, minimize exposure: redact sensitive fields, restrict who can access AI tools, and define retention rules. If you operate in regulated spaces, a custom/on-prem approach may be a better fit.
Which AI response generator tools are good for different use cases?
▾
Some tools are best for general writing (quick replies across platforms), others are best for marketing tone control, and others are built specifically for support or sales workflows.
A fast way to choose: decide where replies happen most (email, chat, helpdesk, CRM), then test drafts on your real conversations. The “best tool” is the one that saves time without damaging trust.
Are AI response generators free, and what does pricing usually depend on?
▾
Many tools offer free trials or limited tiers, then charge via subscription or usage (messages, seats, tokens). Price usually increases when you need team features, analytics, deeper integrations, or stronger customization.
For businesses, compare total cost: tool fee + time saved + support quality + risk reduction. Cheap is not cheap if it creates mistakes or inconsistent brand communication.
Generic tools vs custom build: when should I go custom?
▾
Go with generic tools when you need speed and your replies are fairly standard. Go custom when messaging is part of your competitive advantage: strict brand voice, unique workflows, sensitive data constraints, or deep CRM/helpdesk integrations.
Custom also makes sense when you want ownership: your own rules, your own analytics, your own roadmap. That’s how an AI response generator becomes a business asset instead of a rented feature.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
Voice recognition is no longer a future technology but now a mainstream tool in everything from healthcare and customer service to smart assistants and accessibility and automation systems. It is becoming part of everything from apps and messaging to virtual personal assistants and smart devices in the home.
One of the prime movers towards accomplishing this revolution is the swift evolution in artificial intelligence (AI) and natural language processing (NLP). Speech recognition Python-based solutions fueled by AI have evolved immensely in precision to enable real-time transcriptions, voice command recognition, and multilingual recognition.These technologies are making interactions faster and more efficient, whether it’s for virtual assistants like Siri and Alexa, medical transcription services, or automated customer support systems.
Why Python Speech Recognition?
Among the many programming languages used for voice recognition, Python speech recognition stands out as the top choice for developers. Python’s ecosystem offers several powerful libraries that allow developers to integrate speech-to-text functionalities into applications with minimal effort. Its extensive open-source community and machine learning frameworks make it the go-to language for AI-driven projects.
Here’s why Python is widely used for speech recognition:
- Rich library support – Python offers multiple dedicated speech recognition libraries, such as SpeechRecognition, DeepSpeech, and Vosk, that simplify the integration process.
- Ease and usability – Its programming syntax readability allows one to develop complex voice-based AI systems with much ease and flexibility in use
- Robust machine learning and AI features – Python has direct integration with machine learning and deep learning platforms like TensorFlow and PyTorch to enable organizations to construct highly precise, custom-built speech recognition models.
- Cross-platform compatibility – Such systems work across multiple operating systems, ensuring scalability for web, mobile, and embedded applications.
How Speech Recognition Works in Python
Speech recognition enables machines to understand and process spoken language, converting it into readable text or commands. The tech can also provide voice assistants, in-home devices, automated transcription tools, and voice-free systems. Such systems can be developed in a less complicated way through developments in Python speech recognition and with the aid of sophisticated AI-based tools.
Human speech recognition includes both linguistic processing and machine learning models being used correctly in a very complicated process.
At its core, speech recognition isn’t magic — it’s about turning complex sound patterns into understandable language using advanced models. Modern systems often rely on neural networks and deep learning to improve accuracy far beyond simple dictionary matching.
“Whisper is a machine learning model for speech recognition… capable of transcribing speech in English and several other languages, and… improved recognition of accents, background noise and jargon compared to previous approaches.”
— OpenAI on Whisper (speech recognition system), Wikipedia
That’s why libraries like Whisper, DeepSpeech, and Vosk form the backbone of Python speech projects — they leverage modern machine learning architectures to decode human speech in ways older systems could not.
Key Components of Speech Recognition Python Applications
- Acoustic Modeling. Speech consists of phonemes, which are the fundamental units of sound. The AI systems identify these sounds and match them to their corresponding letters or syllables. Acoustic models enable the recognition of words that sound alike and handle the variations in pronunciation.
- Language modeling. The system then has to organize words and sentences in a coherent order after sensing phonemes. Prediction models enhance recognition by predicting words that most likely follow in a sentence in largely the same manner that autocorrect or predictive input works in cell phones.
- Noise Filtering & Audio Processing. Recognition of speech is not only about recognizing words—participating words must be filtered from ambient noise and sound. Most speech recognition Python libraries come with noise cancellation to enhance the performance in real scenarios, i.e., in the office, in a crowd, or in the context of in-car free hand conditions.
Neural Network Processing. They have the latest speech recognition systems using AI and deep models to improve accuracy levels. Advanced deep models and AI assist the systems in identifying patterns in enormous amounts of spoken data to adapt to accents and dialects and patterns changing with time.
Top Python Speech Recognition Libraries in 2026
Python offers a variety of powerful speech recognition libraries, each suited for different use cases. Whether you need a lightweight API-based tool, an offline speech recognition system, or an advanced deep learning model, there’s a solution available. Below is a comparison of the five best speech recognition Python tools in 2026, covering their strengths, weaknesses, and ideal use cases.
Comparison of Top Python Speech Recognition Libraries
| Library | Type | Strengths | Weaknesses | Best For |
|---|
| SpeechRecognition | Wrapper for multiple APIs | Easy to use, lightweight, flexible, supports Google/IBM/Microsoft | Internet dependent, weak offline support | Quick integration, basic transcription |
| Mozilla DeepSpeech | Offline, open-source, TensorFlow-based | High accuracy, customizable, privacy-friendly | Needs GPU/high CPU, large models | Privacy-sensitive apps, custom AI |
| Vosk | Offline, lightweight | Low latency, multilingual, works on embedded devices | Limited pre-trained models, requires tuning | IoT, Raspberry Pi, smart devices |
| Google Speech-to-Text API | Cloud-based | Very accurate, real-time streaming, auto-punctuation | Subscription costs, needs internet, latency risk | Enterprises, live transcription, call centers |
| OpenAI Whisper | AI-powered, multilingual | Extremely high accuracy, understands accents & noise, context-aware | Heavy resource use, slower on low hardware | Journalism, podcasts, multilingual assistants |
SpeechRecognition
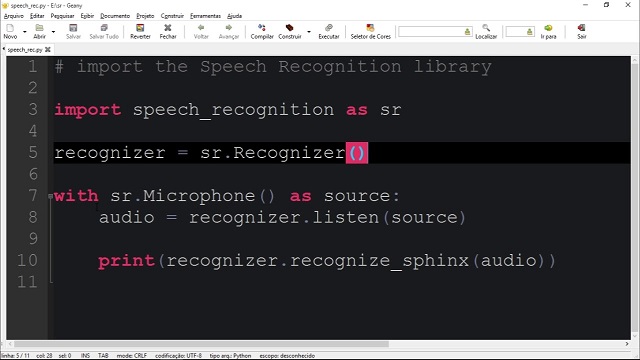
SpeechRecognition is one of the most widely used Python libraries for speech-to-text conversion. It acts as a wrapper for multiple speech recognition engines, making it easy to integrate with cloud-based and offline services. The library supports APIs like Google Web Speech, CMU Sphinx, IBM Speech to Text, Wit.ai, and Microsoft Azure Speech.
Strengths:
- Easy to implement – Requires minimal setup and works with a simple API call.
- Lightweight – Does not require extensive computational power.
- Flexible – Supports multiple speech engines, allowing developers to choose the best fit.
Weaknesses:
- Internet dependency – Most of its features rely on cloud APIs, requiring an internet connection.
- Limited offline capabilities – The CMU Sphinx engine is available for offline use but lacks accuracy compared to deep learning-based alternatives.
Best Use Cases:
- Quick speech recognition integration into Python applications.
- Developers looking for a simple API to access Google or IBM speech services.
- Basic transcription needs where internet access is available.
Mozilla DeepSpeech
Mozilla DeepSpeech is a deep learning-based, open-source speech recognition system built on TensorFlow. It is trained on thousands of hours of voice data and offers high accuracy, even in challenging conditions. Unlike cloud-based solutions, DeepSpeech runs entirely offline, making it suitable for privacy-sensitive applications.
Strengths:
- Fully offline processing – No internet connection required.
- High accuracy with proper training – Can be fine-tuned with custom voice data.
- Open-source flexibility – Developers can modify and improve models based on their needs.
Weaknesses:
- Requires high computational power – Best suited for systems with GPUs or high-end CPUs.
- Large model size – Can be resource-intensive compared to lightweight libraries like SpeechRecognition.
Best Use Cases:
- Privacy-focused applications that require offline speech recognition.
- AI-driven applications needing accurate speech-to-text conversion.
- Developers looking to fine-tune a speech model for a specific use case.
Vosk
Vosk is a lightweight, offline speech recognition Python library designed for low-power devices like Raspberry Pi and embedded systems. It supports multiple languages and provides real-time speech processing with minimal resource consumption.
Strengths:
- No internet dependency – Works completely offline.
- Low latency – Optimized for real-time applications.
- Multilingual support – Recognizes speech in over 20 languages.
Weaknesses:
- Fewer pre-trained models compared to cloud-based APIs.
- Requires additional tuning to improve accuracy for niche applications.
Best Use Cases:
- Embedded systems (Raspberry Pi, IoT applications, smart home devices).
- Developers needing offline speech recognition with minimal hardware requirements.
- Multilingual speech processing for global applications.
Google Speech-to-Text API
Google Speech-to-Text API is a cloud-based speech recognition service that provides highly accurate transcription using Google’s deep learning models. It supports real-time and batch processing, making it suitable for applications requiring fast and scalable speech recognition.
Strengths:
- High accuracy across multiple languages.
- Supports real-time streaming for live applications.
- Includes auto-punctuation and noise cancellation features.
Weaknesses:
- Requires a Google Cloud subscription, which can be expensive for high-volume applications.
- Latency issues may arise in environments with poor internet connectivity.
Best Use Cases:
- Large-scale enterprise applications needing cloud-based transcription.
- Call centers and customer support automation.
- Live streaming applications requiring real-time speech-to-text conversion.
OpenAI Whisper
OpenAI Whisper is an AI-powered speech recognition Python model trained on a massive dataset of multilingual speech. It is designed for high-accuracy transcription, multi-language support, and natural conversation understanding.
Strengths:
- Extremely high accuracy, even with accents and noisy backgrounds.
- Supports multiple languages, making it ideal for global applications.
- AI-driven transcription with improved contextual understanding.
Weaknesses:
- Requires significant processing power for real-time applications.
- Can be resource-intensive compared to lightweight libraries.
Best Use Cases:
- High-accuracy transcription services for podcasts, interviews, and journalism.
- AI-driven voice assistants with multilingual capabilities.
- Businesses needing contextual understanding beyond simple speech-to-text conversion.
Python continues to be a leading choice for developing speech recognition applications due to its extensive library support. Whether you need a simple API-based tool like SpeechRecognition, an offline solution like Vosk, or an advanced AI-powered model like OpenAI Whisper, there is a Python speech recognition library suited for your project.
Choosing between open‑source libraries and cloud‑based speech APIs isn’t just a technical decision — it’s a strategic one. The tradeoffs often come down to control versus convenience.
“Open-source solutions… offer the flexibility to modify the code to meet specific requirements. However, open-source solutions… must be provided and managed by you… Additionally, the accuracy of open-source tools is often inferior to that of cloud-based alternatives…”
— AssemblyAI, “Python Speech Recognition in 2025”
This highlights why many developers start with an API like Google Speech or AssemblyAI for accuracy and then graduate to local, customized systems when they need more control, privacy, or offline capability.
How to Implement Python Speech Recognition in Your Project
Python speech recognition systems have made changing the way that companies automate processes, communicate with users, and process voice data a reality. From virtual assistant-based systems powered by artificial intelligence to voice command and real-time transcription and voice-controlled smart devices, application utilization of speech recognition must be weighed and optimized.
To successfully implement Python speech recognition technology, firms have to select the right library, calibrate processing to realworld specifications and integrate the tool into the process. High accuracy cloud-based APIs are required in some applications while independent and offline models work in others
The secret to an effective speech recognition Python project is finding the ideal balance between accuracy and speed and being in a position to connect well with other systems.
Setting Up a Python Speech Recognition System
Before diving into implementation, it’s important to define what the speech recognition system will be used for. A real-time transcription service requires high-speed processing, whereas an AI chatbot might need natural language understanding in addition to voice-to-text conversion.
Once the use case is clear, the next step is setting up the development environment. This involves installing the necessary Python libraries and configuring the system for optimal performance.
Cloud-Based vs. Offline Speech Recognition
One of the first decisions businesses face when implementing Python speech recognition is whether to use cloud-based or offline speech processing.
Cloud-based services, such as Google Speech-to-Text or OpenAI Whisper, provide high accuracy and continuous improvements because they leverage deep learning models trained on massive datasets. These services are ideal for applications that require real-time, multilingual speech recognition. However, they depend on an internet connection and often come with ongoing usage costs.
Offline models, like DeepSpeech and Vosk, process voice data directly on the device, making them a great choice for privacy-sensitive applications where data security is a concern. These solutions allow businesses to avoid external API costs, but they may require fine-tuning and additional computational resources for training and optimization.
For businesses operating in high-security industries, such as healthcare, finance, and legal services, offline models provide greater control over voice data without relying on third-party providers.
Optimizing Speech Recognition for Accuracy and Performance
The speech recognition model is as good as the quality input it gets. Even the most advanced AI-based systems fail to handle poor quality audio, high levels of background noise, or heavy accents. To have a better recognition percentage, companies need to work on sound optimization and model adjustment from the AI end
Major factors affecting accuracy in speech recognition:
- Audio Quality – High-quality microphones and noise elimination methods enhance speech audibility and produce better transcription accuracy.
- Background noise management – Using sound filtration and noise cancellation techniques enables speech models to tune in to the voice of the speaker
- Speaker Adaptation – Training models to recognize multiple accents and speaking patterns ensures higher accuracy to multiple clusters of users
- Word Choice Within Domain – Training models to a domain-specific lexicon increases awareness to business-specific usage
For multiple language applications, multiple language support will be required. There exist Python speech recognition libraries that natively support multiple languages and those that allow multiple language support through changing between multiple models trained in different languages. Business organizations that have international scope should prefer solutions with robust language processing
Integrating Speech Recognition into Business Applications
Speech recognition technology is now being widely adopted across various industries, providing businesses with new opportunities for automation and customer interaction. The implementation of this technology depends on the specific use case and industry requirements.
depends on the specific use case and industry requirements.
Real-World Business Applications of Python Speech Recognition:
- AI-powered Customer Service – Virtual and AI-powered chatbots utilize speech recognition to comprehend the inquiries of the customers and respond automatically.
- Medical Transcription Services – Physicians would not be depending on speech-to-text systems to auto-document along with note-taking.
- Financial & Legal Transcription – It reduces paperwork in financial reports and legal cases and client conversations
- Hand-Free devices for Smart devices – Devices with IoT such as voice assistant smart home devices and voice command in vehicles use voice recognition to offer hand-free services.
- Live Captioning & Subtitling – Automatic transcription tool helps organizations produce live captions in real-time online conferences, webinars, and live streams.
Each of these use cases requires different levels of accuracy, latency, and language processing capabilities, making it essential to choose the right speech recognition Python solution for the job.
Ensuring Scalability and Security in Speech Recognition Applications
Scalability is a paramount concern for businesses handling vast volumes of voice data. A speech recognition system must be capable of handling thousands of interactions simultaneously without compromising speed or accuracy.
Security is also an important concern, particularly when dealing with sensitive user data. Some industries, such as finance, healthcare, and government, must comply with strict data privacy regulations like GDPR and CCPA.
To ensure compliance, businesses should consider:
- On-premises speech recognition solutions for greater control over data.
- End-to-end encryption for protecting voice interactions.
- AI bias mitigation to prevent inaccuracies based on speaker demographics.
Balancing performance, security, and cost-efficiency is essential for businesses that rely on AI-powered speech recognition for mission-critical applications.
Challenges and Limitations of Speech Recognition
While Python speech recognition has advanced significantly, real-world implementation comes with several challenges that affect accuracy, speed, and user experience. Companies implementing speech-to-text solutions need to overcome technical constraints to support fluent and seamless functioning.
Background noise is one of the biggest issues. In noisy environments like offices, public spaces, and call centers, speech recognition models struggle to distinguish the speaker’s voice from background noises, simultaneous conversations, or echoing acoustics.This leads to continuous misinterpretations, which makes the system less reliable.
Another challenge is dialect and accent recognition. While many speech recognition Python models are trained on standardized datasets, they often fail to accurately process regional accents, fast speech, or non-native pronunciations. This can result in incorrect transcriptions or repeated errors, making the system frustrating for diverse user groups.
Latency is another concern, particularly for real-time speech recognition applications. Systems requiring real-time voice-to-text transformation, such as AI chatbots or live transcription software, need to maintain processing latency as low as possible. High latency can make interactions respond slowly or become unresponsive, affecting user experience in a negative manner.
To overcome these limitations, businesses optimize their speech recognition models using noise reduction filters, AI-powered learning, and continuous model fine-tuning. By adapting speech recognition Python solutions to real-world conditions, companies can significantly improve accuracy and performance.
Scrile AI: The Best Custom Development Service for Python Speech Recognition
Businesses looking to implement speech recognition Python solutions need more than just an off-the-shelf API—they need a customized, scalable, and efficient system that seamlessly integrates with their existing workflows. Scrile AI offers a tailored approach to speech recognition development, ensuring that businesses get precisely the features, accuracy, and performance they need.
Contrary to typical cloud-based applications limiting personalization and control, Scrile AI provides fully customized speech recognition models, designed for industry-specific use. Customer service automation, medical transcription, legal documentation, or voice-based smart apps, Scrile AI provides cutting-edge AI solutions on the basis of proprietary business requirements.
Why Choose Scrile AI Over Off-the-Shelf Solutions
| Option | Ownership | Customization | Security | Scalability | Integration | Weak Points |
|---|
| Off-the-Shelf APIs (Google, IBM, etc.) | Belongs to provider | Limited, generic models | Provider-dependent compliance | Scales with cost | Easy to plug & play | Vendor lock-in, recurring fees |
| Open-Source Models (Vosk, DeepSpeech, Whisper) | Open community | High, but requires expertise | Depends on implementation | Flexible, but resource heavy | Needs dev effort | Requires AI/ML specialists |
| Scrile AI (Custom Python Development) | Full client ownership | Tailored to industry (medical, legal, finance, support) | GDPR/CCPA compliant, business-grade | Enterprise-level, low-latency, live-ready | Seamless integration into existing apps | None — handled as turnkey by Scrile |
What Scrile AI Offers
Scrile AI specializes in custom-built AI solutions, allowing businesses to leverage advanced Python speech recognition technology while maintaining complete ownership and flexibility over their systems.
- Custom speech recognition models – Tailored for specific industries to give higher accuracy in specialized vocabulary and use cases.
- Seamless integration – Integrates with existing apps, software environments, and backends without problems of compatibility.
- Scalable infrastructure – Designed to process live voice handling with high-speed transcription and low latency.
- Multilingual speech recognition – Supports multiple languages and dialects, making it ideal for global businesses.
Why Choose Scrile AI Over Off-the-Shelf Solutions?
The majority of companies begin with third-party APIs but later discover that pre-existing solutions are significantly limiting. Scrile AI escapes vendor lock-in and platform limitations and offers:
- End-to-end bespoke AI models – No reliance on third-party, and thus companies will fully own their technology.
- Business-class security – GDPR, CCPA, and other data privacy law compliant, hence secure and safe voice data processing.
- Support and scalability – Engineered for businesses who need long-term stability, upkeep, and nurturing for mass scale operations.
For businesses serious about building powerful, AI-driven voice solutions, Scrile AI provides the best Python speech recognition development service available. Explore Scrile AI’s custom AI solutions today and bring advanced speech recognition capabilities to your business.
Conclusion
The landscape of Python speech recognition is evolving rapidly, with numerous libraries that offer advanced features for real-time transcriptions, AI assistants, and voice automation. The choice of the appropriate tool depends on your needs, levels of accuracy, and scalability objectives.
For businesses that require custom solutions, relying on pre-built APIs may not be enough. Scrile AI provides tailored AI development, ensuring full control, security, and seamless integration into any application.
Take the next step—explore Scrile AI today and build a custom AI-powered speech recognition Python system.
FAQ – How to Create a Telegram Bot (BotFather, Bot API, AI, Monetization)
Answers to the questions people ask after they launch their first bot: setup, hosting, rate limits, payments, and adding AI.
How do I create a Telegram bot with BotFather?
▾
Open Telegram, find @BotFather, and use /newbot. You’ll set a display name, pick a username ending in “bot,” and receive an API token.
Treat the token like a password. Store it in environment variables (not in public repos), rotate it if it leaks, and never paste it into screenshots or tutorials.
Webhook vs long polling: which one should I choose?
▾
Webhook is the production-friendly option: Telegram pushes updates to your server instantly, which improves responsiveness and reduces wasted requests.
Long polling is great for prototypes because it’s simple, but you still need to handle retries, timeouts, and process restarts. If you’re building something serious, plan to move to webhooks.
What stack is best for Telegram bots in 2026?
▾
For most teams, Python or Node.js wins because libraries are mature and deployment is straightforward. In Python, aiogram (async) and python-telegram-bot are popular. In Node.js, many teams use Telegraf or grammY.
Choose based on your product, not hype: async support, webhook handling, middleware, and how easily you can integrate databases, payments, and analytics.
Where do I track Telegram Bot API updates?
▾
The safest habit is to check the official Bot API documentation’s “Recent changes” section before big releases or feature launches.
If you want updates in real time, follow Telegram’s bot-focused channels (news + discussion) so you catch UX-breaking changes early, not after your users report bugs.
How do I handle rate limits, flood control, and 429 errors?
▾
Don’t brute-force retries. When Telegram returns flood control, it often includes a retry_after value. Respect it, wait, then retry.
In production, you’ll want an outgoing message queue that smooths bursts (especially broadcasts). Treat rate limits as a product constraint: design flows that don’t spam users or hammer the API.
Is the Telegram Bot API free, and what are “paid broadcasts”?
▾
The Bot API itself is free to use, but broadcasting has practical limits. For large newsletter-style sends, Telegram introduced Paid Broadcasts, which can raise throughput when you pay per message using Telegram Stars.
This matters for architecture: if your business depends on mass sends, budget for it (or design batching/segmentation that fits the free limits).
Can I monetize a Telegram bot?
▾
Yes—Telegram bots are often monetized through subscriptions, paid access to channels, one-time purchases, lead-gen funnels, and donations. The bot becomes the “checkout + delivery” layer right inside the chat.
The important part is consistency: access rules, renewals, user states, and support flows must be automated. A monetized bot fails when payments work, but delivery and permissions are managed manually.
How do I add AI (ChatGPT-like) features to a Telegram bot?
▾
AI bots are usually a combination of Telegram messaging + your AI backend. Your bot receives updates, sends user text to an LLM endpoint, then streams back a clean answer (often with typing indicators and short chunks).
To make it feel “human,” keep context per user, add safe fallbacks, and control costs with message limits, caching, and smart prompt design. AI isn’t just the model—it’s the whole product loop.
How do I keep my Telegram bot secure?
▾
Start with basics: protect the token, validate webhook requests, and avoid logging sensitive user content. If you store user data, keep it minimal and encrypt secrets.
Security is also operational: monitor for spikes, lock down admin commands, and separate “public bot logic” from internal tools. The fastest way to lose trust is a bot that leaks tokens or mishandles payments.
When should I build a custom bot instead of using a no-code builder?
▾
No-code is perfect for testing an idea. Custom development becomes worth it when the bot is core to your business: you need full branding, deeper integrations, higher performance, custom monetization, or strict control over data and UX.
If your bot needs to scale beyond “a helpful helper” into a product, a custom architecture (queues, analytics, payments, admin tools) saves you from platform limits later.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
AI avatars have moved far beyond cartoon filters and novelty apps. In 2026, they’re redefining how we present ourselves online — from personalized content on social media to branded spokespeople in marketing videos. Whether you’re an individual creator or part of a business team, a high-quality AI-generated avatar can act as your always-ready digital twin.
AI avatars in 2026 are no longer just “fun filters”. Today, the best AI avatar generator can create realistic photo avatars for profile pictures, stylized characters for social media, and even talking video presenters for business content.
This guide focuses on what people actually search: best AI avatar generator (2026), top-rated AI avatar creator tools, and AI platforms with top photo avatar features. We’ll compare the most practical options across three outputs: (1) photo-to-avatar portraits, (2) talking video avatars, and (3) 3D avatars for apps and games—so you can pick the right avatar maker AI for your use case.
An AI avatar generator uses artificial intelligence to create lifelike representations of people — animated, still, or even interactive — based on photos, prompts, or style presets. And the quality? Better than ever. Advances in AI and visual processing have made it easier to generate avatars that feel expressive, realistic, and customizable.
The shift from simple filters to full-fledged digital selves isn’t just a visual upgrade. Analysts who study online identity point out that AI avatars are quickly becoming part of how people actually exist in virtual spaces.
“AI avatars are not just futuristic novelties—they are quickly becoming foundational elements of online identity in the metaverse and beyond.”
— Evelyne Hoffman, WINSS Solutions
This aligns with what we see in 2026: when you choose an AI avatar generator, you’re not just picking a fun effect. You’re choosing the engine behind your digital presence across social media, games, virtual meetings, and future metaverse platforms.
In this guide, we’ll help you find the best AI avatar generator for your needs — whether you’re looking for free tools, mobile apps, or advanced solutions that create avatars from scratch. Let’s dive into the tools shaping digital identity in 2026.
Top 7 AI Avatar Generators in 2026
| Tool | Best For | Strengths | Limitations |
|---|
| Synthesia | business talking avatars (video) | Talking avatars, multilingual voice, business-ready | Paid-only features, limited styling |
| MagicShot AI | Social media visuals | Huge style variety, easy to use | No video/animation, photo quality dependent |
| Fotor AI Avatar | Influencers & coaches | Beginner-friendly, solid headshots | Static images only |
| Picsart AI Avatar | Gen Z & casual creators | Fast, vibrant, mobile-first | Limited realism, subscription for full use |
| Ready Player Me | Gaming & VR | 3D full-body avatars, engine integration | Technical setup, fewer 2D options |
| Reface App | Viral animated content | Fun, animated avatars, free/low-cost | Not high-res, privacy concerns |
| Lensa AI | photo avatars (artistic packs) | Painterly, fantasy & Instagram-ready | Style packs can be pricey |
If you want review-backed ‘top-rated’ options, check verified review aggregators like G2’s AI Avatar Generators category.
How We Chose These Generators

Selecting the best AI avatar generators is less about exceptionally high-quality graphics. From numerous dozen tools released annually, we focused on those aspects of highest value to users — whether you’re developing content to post to Instagram, making character assets to integrate into your game, or building a virtual representative of your business.
First and foremost, realism was at issue — just how realistic the avatars look and move. An advanced digital character needs to be immersive and never off-putting nor robotic. Other than that, diversity mattered. We wanted to have software where users can create avatars with different styles, body types, and moods.
Usability was paramount as well. Some websites don’t require any design experience at all, and others need you to have some level of technical know-how. We considered both options.
We balanced free versus paid features — not just what’s free, but whether or not paid tiers are worth it.
Finally, we looked at output quality. Does the generator produce still images, animated avatars, or video-ready content? Can the files be used across social media, YouTube, game engines, or enterprise platforms?
From creators to marketers to indie game devs — these tools have use far beyond novelty. So we picked solutions that truly deliver.
Detailed Reviews: Top AI Avatar Software (2026)
Not all AI avatar tools are built the same. Some focus on hyper-realistic video avatars for business, others on stylized portraits for social media. Whether you want to make an AI avatar for your Twitch profile, marketing campaign, or personal brand, there’s a tool out there tailored to your needs.
We’ve tested and compared dozens of popular platforms and narrowed it down to seven that really stand out in 2026 — based on realism, features, ease of use, and the kind of content you can create. From polished video presenters to artsy cartoon styles, here’s our take on the best of the best.
Synthesia

If your goal is to create video avatars that actually talk — not just static profile pics — Synthesia is a strong contender. Originally built for corporate training and explainer videos, it’s now used by marketers, educators, and small business owners who want to replace on-camera filming with smart, polished AI presenters.
The process is simple: choose an avatar, type your script, and let the system turn it into a video with realistic lip-syncing. You can also clone your own voice and use your own avatar if you’re on a higher plan.
That straightforward workflow is exactly why tools like Synthesia became popular with training and marketing teams. Even the company’s own product messaging emphasizes how far AI avatars have come as a replacement for traditional video production.
“Produce studio-quality videos with AI avatars and voiceovers in 140+ languages. It’s as easy as making a slide deck.”
— Synthesia
This quote reinforces the use case you describe: Synthesia isn’t about fun profile pics — it’s about scalable, multilingual, business-ready video. In your review, it underlines why you put Synthesia at the “professional video avatar” end of the spectrum, compared to more casual selfie-style generators later in the article.
Strengths
- High-quality avatars with natural motion and expression
- Multilingual voice support
- Ideal for explainer videos, training content, and branded video messaging
Limitations
- Not great for casual users or creative expression — very business-focused
- Requires a paid plan for most features
- Limited customization of avatar appearance in lower tiers
Synthesia isn’t the best AI avatar app for selfies or fun — but it’s excellent if you need professional, video-ready avatars at scale. Think: onboarding videos, product walkthroughs, or educational content where you want a consistent, polished look.
MagicShot AI
MagicShot AI is built for people who want to create multiple versions of themselves — not just one perfect selfie. It’s especially popular with social media users, digital creators, and professionals looking to generate a wide range of stylized portraits for content and branding.
Upload a few photos, choose your styles, and the platform spits out dozens of unique AI-generated avatars: cartoon, cyberpunk, watercolor, anime, fashion editorial — you name it. It’s easy to use, and most results look polished enough to use as profile pictures, thumbnails, or promo visuals.
Strengths
- Huge variety of artistic styles
- Simple interface with no learning curve
- Great for creating eye-catching content fast
Limitations
- Mostly image-based — no video or animation support
- Not suited for professional business use (e.g., training videos)
- Best results require high-quality photo input
If you’re looking for the best AI avatar creator to experiment with different aesthetics or update your personal brand visuals, MagicShot AI is a fun, flexible option.
Fotor AI Avatar Generator
Fotor has been around as a photo editor for years, but its AI avatar generator has become a standout feature in 2026. It’s a great choice for anyone who wants quick, creative avatars without diving into complex tools or pricey subscriptions.
The Fotor AI Avatar Generator lets you generate dozens of avatars by uploading a few selfies — similar to Lensa or MagicShot — but with smoother output and better color harmony. It leans toward polished, semi-realistic styles with just enough flair to make your avatars pop on social media or websites.
Strengths
- Accessible to beginners
- Reliable output even with average-quality photos
- Includes editing tools to tweak results
Limitations
- Mostly focused on headshots
- Limited to static images
- Some features hidden behind a paywall
If you’re searching for the fotor AI avatar generator that balances speed, quality, and ease of use, this is an easy one to recommend — especially for influencers, coaches, and creators.
Picsart AI Avatar
If you’re already familiar with Picsart as a creative editing app, you’ll be glad to know its AI avatar generator online tool is just as intuitive. It’s geared toward casual creators, Gen Z users, and anyone who wants a personalized digital look for their socials without spending hours tweaking settings.
Upload a handful of selfies, and you’ll get back stylized avatar sets in various aesthetics — futuristic, dreamy, gritty, cartoonish. The avatars are clearly AI-generated, but that’s part of the appeal: they’re bold, vibrant, and perfect for platforms like TikTok, Instagram, or Discord.
Strengths
- Mobile-first, quick, and fun to use
- Great for personal branding and content creation
- Integrated with Picsart’s broader editing tools
Limitations
- Limited realism — not great for business use
- Subscription needed for full access
- May repeat certain looks if you don’t upload diverse photos
As an AI avatar generator online, Picsart hits the sweet spot for users who value speed, color, and content-ready visuals over ultra-precise realism.
Ready Player Me
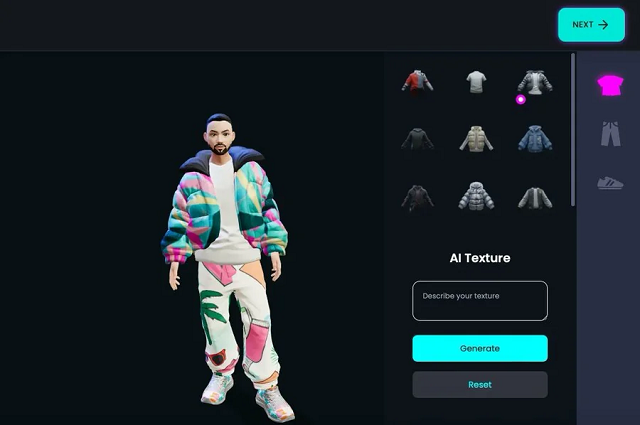
Ready Player Me takes avatars into the world of 3D. If you’re building a virtual world, VR experience, or game — or just want a fully rigged 3D version of yourself — this is hands-down the best avatar generator in that space.
It’s especially popular among developers and game designers because of its wide compatibility with Unity, Unreal Engine, and WebXR. You start by uploading a selfie, and the platform creates a full-body avatar you can customize in style, outfit, and movement. It’s also used in virtual meetings, social VR platforms, and metaverse-style apps.
Strengths
- Generates ready-to-use 3D avatars
- Integrates well with development pipelines
- Ideal for gaming, VR, and interactive platforms
Limitations
- More technical than image-based avatar apps
- Requires understanding of game engines for full use
- Limited options if you’re looking for stylized 2D content
If you’re building for Web3, gaming, or immersive tech, this may be the best avatar generator for bringing your virtual self to life in real-time environments.
Reface App
Reface made a name for itself with real-time face-swapping and viral deepfake content, but its newer avatar tools have given it a fresh edge in 2026. If you’re after quick, animated, personality-filled avatars for memes, messages, or fun promos, this might be the best free AI avatar generator for you.
The app lets you create animated avatars that lip-sync, emote, and mimic expressions. It’s not meant for polished professional output — but that’s exactly why it works so well on platforms like TikTok, Snapchat, and Reels. It’s fast, weirdly accurate, and way more engaging than a still image.
Strengths
- Totally mobile, built for viral content
- Includes animated avatars and motion-based templates
- Many features are free or low-cost
Limitations
- Not business-oriented
- Output isn’t high-res enough for large-scale media use
- Data/privacy concerns with some users
If you’re focused on fun, humor, or storytelling, this is one of the best ways to experiment without spending a dime. For sheer personality, it’s a standout among the best free AI avatar generator options.
Lensa AI (by Prisma Labs)

Lensa exploded in popularity for its dreamy, highly stylized portraits — and its best AI avatar maker features in 2026 continue to deliver. It’s designed for people who want something more aesthetic than realistic: think painterly effects, fantasy themes, and Instagram-worthy images.
Upload 10–20 photos, choose a style pack, and get back dozens of variations. Some look cinematic, some lean into anime or fantasy, and others have that bold digital art vibe that works great for personal branding or content aesthetics.
Strengths
- High-quality, artistic results
- Super easy to use with a sleek mobile interface
- Beautiful filters and visual themes
Limitations
- No animation or video options
- Style packs can get expensive
- Output sometimes over-processes faces
As a best AI avatar maker, Lensa isn’t built for corporate needs — but it’s perfect if you want avatars that feel more like art than identity. Creators, freelancers, and influencers will find a lot to love here.
AI Platforms With Top Photo Avatar Features
If your main goal is a photo avatar (PFP, headshot, profile branding), the winning features are: photo similarity control, style variety, face consistency across packs, and clean outputs that don’t “melt” details.
Best picks for photo avatars:
– Lensa AI — strongest for artistic style packs and “Instagram-ready” portraits.
– Fotor — quick conversion from selfies with multiple styles (good for speed).
– Picsart — flexible avatar maker from photo or even video input, plus editing tools.
Custom-Built AI Avatar Generators: Scrile AI as Your Development Partner
Choosing the best AI avatar generator is great if you’re creating content for fun or personal branding. But what if your goal is bigger — launching your own product, offering avatar features in your app, or building something truly custom that no one else has? That’s where Scrile AI becomes more than just a name — it becomes your technical partner.
Scrile AI is not a tool, template, or marketplace. It’s a custom software development service that helps startups, businesses, and creators build their own AI avatar generator from scratch — fully tailored to their goals, user experience, and branding. You bring the idea. Scrile brings the engineering, AI models, and product infrastructure to make it real.
Custom-built avatar systems make the most sense when you zoom out and look at the business potential. Virtual influencers and human-like digital personas are no longer a niche experiment — they’re a fast-growing global market.
“The global virtual influencer market size was estimated at USD 6.06 billion in 2024 and is projected to reach USD 45.88 billion by 2030.”
— Grand View Research
For founders and teams who want to launch their own avatar-based product, numbers like this validate the idea of investing in a custom AI avatar generator. Scrile AI fits into that picture as the technical partner that turns those market opportunities into an owned platform instead of just another account on someone else’s SaaS.
Their team can build advanced functionality, including:
- AI-powered face generation and photo-to-avatar transformation
- Model training for custom styles, voice, animation, and emotional expression
- Support for real-time video avatars, screen recording, and voiceovers
- Workflow integration with messaging, content publishing, and user accounts
- Custom dashboards for managing avatars, user data, and moderation
Most tools on the market force you into their limitations. With Scrile AI, you build your own product — not rent space in someone else’s. That means full ownership of your technology, your data, and your brand. No subscription traps. No API rate limits. No licensing headaches.
Want your avatars to look, sound, and move the way you envision? Want to sell avatar-based content directly to your users? Scrile builds that for you — tailored to your market and tech stack.
If you’re ready to move from user to creator, and from idea to product — get in touch with Scrile AI. Your custom avatar solution starts with one smart conversation.
Off-the-Shelf Avatar Tools vs. Scrile AI (Custom Build)
| Option | Ownership & Branding | Capabilities | Monetization | Best Fit |
|---|
| Pre-Built Generators (Synthesia, Lensa, etc.) | Limited control | Fixed styles & features | None | Individual users & creators |
| Scrile AI (Custom Solution) | Full ownership & branding | Custom avatars, animation, voice, integration | Subscriptions, tipping, content sales | Businesses & platforms |
Conclusion
AI avatar generators have come a long way — from novelty filters to powerful tools used across marketing, gaming, education, and content creation. The options available in 2026 are more diverse, realistic, and customizable than ever. Whether you’re looking to boost your personal brand, add some personality to your social presence, or automate your company’s video content, there’s a best AI avatar generator out there for you.
If your goals go beyond using what already exists — if you want to build your own solution, control the user experience, and scale on your terms — Scrile AI is the partner you need. Their team helps businesses and creators develop custom avatar software with full ownership and flexibility baked in from the start.
Ready to take that next step? Reach out to Scrile and turn your vision into a tailored AI avatar platform that stands out from the crowd.
FAQ – Best AI avatar generators (2026)
What is an AI avatar generator and what can it create in 2026?
An AI avatar generator is a tool that creates a digital version of a person from photos, prompts, or preset styles. In 2026, “avatar” can mean three very different outputs: (1) photo-style portraits for profile pictures, (2) talking video avatars for marketing or training, and (3) 3D avatars you can use in apps, games, or VR.
The best tool depends on your target output. A great selfie-to-portrait app may be useless for video presenters, and a strong 3D pipeline may not produce the clean headshots you want for a personal brand.
What’s the best AI avatar generator for realistic profile photos and headshots?
For realistic headshots, prioritize face similarity and “clean detail” (eyes, teeth, hairline, glasses). The best results usually come from tools that let you keep identity stable instead of pushing heavy stylization packs.
A quick test: generate 20–40 images and check whether you still look like you in at least half of them. If the outputs drift, switch to a tool with stronger similarity controls, or reduce style variation and keep one consistent look.
What’s the best free AI avatar generator, and what are the real limits?
Free tiers are great for trying the workflow, but they usually limit output quality or control. Common restrictions include fewer generations per day, watermarks, lower resolution exports, or fewer options to lock face similarity.
If you only need a fun avatar for a profile picture, free can be enough. If the avatar becomes part of a brand asset (ads, courses, product UI), paying is often worth it for higher resolution, better consistency, and clearer licensing.
Which AI avatar tools are best for talking video avatars (AI presenters)?
Talking video avatars are a separate category from portrait generators. Here you want stable lip-sync, natural facial motion, decent voice options, and an export workflow that fits real use (training, onboarding, product explainers, sales videos).
For business content, look for script-first tools with multilingual support and consistent output across many videos. The goal is a reliable presenter you can reuse—without your avatar changing face shape or “mood” every time you export.
What’s best for 3D avatars for games/VR and app integration?
For games and VR, you need a real 3D pipeline: a full-body mesh, good rigging, and export formats that work in your engine (Unity/Unreal/WebXR). A beautiful 2D portrait doesn’t help if the avatar can’t move naturally.
Compare tools by rig quality, customization depth (outfits/body types), animation readiness, and how much manual cleanup is required. The “best” option is often the one that integrates cleanly into your build, not the one with the prettiest promo images.
How many photos should I upload to get a good AI avatar?
Most tools perform best with 10–20 photos. Use good lighting, sharp focus, and a mix of angles (front, 3/4, side). Include a few expressions, but avoid extreme facial distortions.
Skip filtered images, heavy beauty edits, sunglasses, and low-light party photos. If your avatars look “off,” the fastest fix is usually better input photos—not more prompt tweaking.
How do I keep my face consistent across multiple avatar generations?
Consistency comes from strong training images plus tighter variation settings. If the tool offers “face similarity,” “identity lock,” or “reference strength,” raise it when you need a stable persona (for branding or repeated content).
Also reduce style chaos. Jumping between many aesthetics (anime → hyper-real → fantasy) increases identity drift. Pick one direction, generate in batches, and refine within that look.
Is it safe to upload my photos to AI avatar apps?
Safety depends on the platform and your own privacy habits. Before you upload personal photos, check whether images are stored, how long they’re retained, and whether you can delete your data. If those details are missing or vague, treat it as a red flag.
Use a separate email, avoid uploading sensitive/identifiable images (IDs, uniforms, family photos), and don’t reuse your “most personal” photo set across multiple unknown apps.
Can I use AI-generated avatars commercially (branding, ads, courses)?
Often yes, but you must check the tool’s license. Some services allow commercial use only on paid plans, or restrict certain templates/styles. Look for clear terms around commercial usage, resale, and marketing.
If the avatar will be part of a serious business asset, choose a provider with transparent licensing and a support channel. Ambiguous terms are fine for a fun profile picture, but risky for paid campaigns or product UI.
When should a business build a custom AI avatar generator instead of using a tool?
Custom development makes sense when avatars are a core product feature—like a creator platform, a virtual influencer studio, a game/app with identity, or a business tool with branded video presenters and controlled outputs.
A custom build can give you full control over the UI, moderation rules, monetization, and data ownership—plus it reduces platform risk when your roadmap depends on features that SaaS providers can change or remove.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
The webcam chat industry has come a long way from simple one-way video streams. In 2026, platforms are expected to do more than just connect users—they need to engage, monetize, and scale. Live video alone isn’t enough. Audiences now expect private chat options, tipping systems, interactive overlays, and flawless streaming across all devices.
The webcam business is no longer a tiny niche — it’s a full-scale industry with serious money and serious competition. Studios and solo creators now fight for attention on a global level.
“Take adult web-camming, for example, a billion-dollar global industry in which content creators build up devoted followings as they stream themselves to meet endless demand.”
— Lily Hay Newman, WIRED
That level of demand is exactly why your tech stack can’t be an afterthought. If your script can’t keep streams stable and interactive, viewers will simply move to the next site.
That’s where script chat cam solutions come into play. Instead of building everything from scratch, entrepreneurs and studios can launch fully functional platforms using pre-built or custom scripts that handle video, chat, payments, moderation, and more. These tools offer the control and flexibility needed to shape a brand, while also giving creators and performers the tools to earn and interact in real time.
This article explores the top five script chat cam solutions available in 2026. Whether you’re launching a new cam site or upgrading your existing setup, these tools can help you deliver a polished, profitable experience without compromising on features or performance.
Quick Answer: What Is the Best Script Chat Cam Solution?
The best script chat cam solution depends on what kind of webcam business you want to run. A small solo launch can start with a simpler pay-per-minute script. A studio or branded cam platform needs more than video chat: token wallets, performer dashboards, private shows, moderation, payout logic, payment gateway support, and room-level analytics.
If you only need to test demand, a plug-and-play script may be enough. If your platform will depend on adult-friendly payments, custom performer workflows, branded UX, affiliate traffic, and long-term ownership, choose a stronger foundation such as a custom or white-label webcam platform instead of a basic script.
What Makes a Great Script Chat Webcam Tool?
A solid script chat webcam solution is more than just a video player and a chatbox. At its core, it combines real-time video streaming with interactive chat, integrated billing, performer dashboards, admin controls, and user management—all built to support high-volume traffic and monetization.
But not all scripts are created equal. Stability and stream quality should come first. If a broadcast lags or drops, users leave. The interface matters too: performers need intuitive tools to manage shows, while viewers want smooth navigation and fast interaction.
Built-in payment options—like credit card billing, tokens, or crypto—are essential. Add moderation tools to prevent abuse, and you’ve got a platform that’s safer for everyone. Finally, look for scripts that support various revenue streams: pay-per-minute shows, tips, locked content, and private sessions.
Choosing the right solution from the beginning helps avoid major technical headaches later and lays the foundation for scaling your platform with confidence.
Tipping, tokens and paid gifts aren’t just “nice extras” anymore — they’re how viewers actively participate in shows and how performers turn attention into income. For modern cam platforms, that engagement layer is part of the core product, not a bonus feature.
“Livestream gifting is no longer a niche feature; it is a mainstream cultural and economic force, redefining entertainment and building deeper audience connection.”
— TikTok & Ipsos, “The Creator Economy Redefined: How Interactive Livestream Gifting is Transforming Entertainment”
When you evaluate script chat cam solutions, look closely at how they handle tips, gifts and tokens. The better they support this “participation economy,” the easier it is for your performers and studio to grow revenue.
Top 5 Script Chat Cam Solutions in 2026
If you’re building a cam platform this year, choosing the right script chat cam tool can make or break your launch. Here’s a rundown of five standout solutions—each offering something different for startups, studios, and growing platforms.
| Solution | Best for | Strongest use case | Main limitation | Launch type |
|---|
| Video Chat Script / Soft112-style tools | Small tests and low-budget launches | Basic pay-per-minute webcam chat | Limited scaling, dated stack, weaker customization | Quick but fragile |
| Online-Webcam.net | Fast turnkey webcam site launch | Templates, performer accounts, payment gateway setup | May require design modernization for a premium brand | Plug-and-play |
| PaidVideoChat by VideoWhisper | WordPress-based PPV or PPM video chat | Private shows, tips, virtual wallet, performer/client roles | WordPress setup and technical configuration still matter | Moderate setup |
| xCams by Adent.io | Professional cam platforms with dev resources | Token billing, dashboards, moderation, HD streaming | Not ideal for non-technical founders without implementation support | Custom-oriented |
| Scrile Stream | Branded webcam businesses built for long-term growth | Private shows, tipping, content sales, affiliate tools, admin control | Not a cheap one-click script; it fits serious platform launches | White-label / custom launch |
Video Chat Script (Soft112)
This script is best known for its simplicity and straightforward pay-per-minute functionality. It includes a performer interface, admin dashboard, and multi-cam support for models, making it a decent pick for small teams or solo entrepreneurs starting out. It does the bare minimum like video chat and session billing, but otherwise, choices are limited. There isn’t a lot of customization, so expanding larger may mean expanding out of it. But it’s a fast and inexpensive way to get your foot in the cam door without a lot of initial investment.
Online-Webcam.net
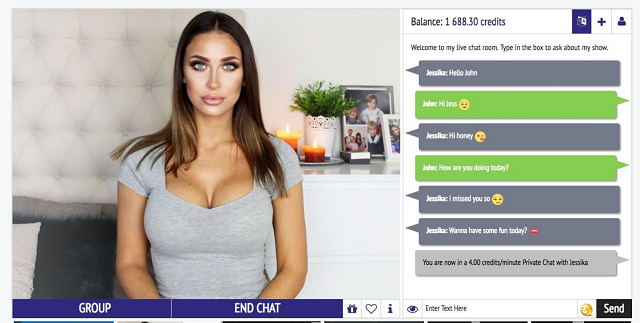
Designed for fast deployment, this option gives users an entire plug-and-play site—complete with templates, performer accounts, and payment gateway support. It’s surprisingly flexible for a ready-made package. Performer dashboards are customizable, and it includes tools for show scheduling and revenue tracking. The only drawback is its slightly dated front-end design. It’s a practical pick for those who want to launch quickly and tweak things as they go, without building a platform from scratch.
PaidVideoChat by VideoWhisper
PaidVideoChat by VideoWhisper is a live video chat script tailored for pay-per-minute models, tipping, and interactive webcam chat. It’s ideal for platforms that want flexibility around pricing and session formats. The script supports private shows, multi-host interactions, mobile streaming, and can integrate with WordPress. It’s more technical to configure than some turnkey platforms, but makes up for it with performance and monetization depth.
xCams by Adent.io
xCams by Adent.io is a white-label live cam site script with a focus on professional-grade performance and customization. It includes high-definition streaming, user and performer dashboards, token-based billing, and advanced moderation features. It is built for businesses that want to launch serious platforms with room to scale. It’s not a plug-and-play tool—you’ll want a developer or their team’s assistance—but in return, you get full control over how your cam site functions and grows.
Scrile Stream
Not a script in the traditional sense—Scrile Stream is a custom development solution. It offers flexibility far beyond plug-and-play tools, making it ideal for those wanting a branded platform with long-term growth in mind. More on that in the next section.
Scrile Stream: The Best Development Solution for Your Webcam Business
Unlike plug-and-play scripts, Scrile Stream offers a custom-built cam site solution tailored to your business model. It’s not just another template—it’s a full development service designed to launch powerful, branded platforms with real-time streaming, interactive chat, tipping systems, paid messages, and virtual tokens.
Scrile Stream also comes equipped with essential tools like affiliate program support, payment gateway integration, and moderation features that help keep your platform safe and monetized. It’s ideal for entrepreneurs who need more than a basic out-of-the-box system.
What sets it apart? Total control. No vendor lock-in, no design limitations, and full ownership of your platform’s code and user experience. If you’re looking for a serious script chat cam alternative with room to scale, Scrile Stream delivers.
That’s the real dividing line between a quick script and a long-term platform: do you truly own the environment your business runs on, or are you renting space under someone else’s rules? Free and semi-free platforms always come with hidden trade-offs.
“Platforms like YouTube or Facebook Live offer free video hosting. But you pay in other ways through limited control, platform ads and lack of ownership.”
— “Video Streaming Hosting in 2025: Best Platforms, Tips & Cost Breakdown”, Bluehost
Scrile Stream follows the opposite logic: you invest in a solution where streaming quality, branding, monetization and data stay under your control, instead of being trapped inside another company’s ad-driven ecosystem
Plug-and-Play Scripts vs. Scrile Stream
| Option | Ownership & Branding | Scalability | Monetization Depth | Support |
|---|
| Typical scripts (Soft112, VideoWhisper, etc.) | Limited, template-based | Harder to expand beyond basics | PPM, tips, private shows | Varies / limited |
| Scrile Stream | Full code ownership, branded UI/UX | Built for growth (enterprise-ready) | PPM, tips, tokens, paid messages, affiliate programs | End-to-end dev & support |
Conclusion: Launch Smarter with the Right Script Chat Cam Solution
A good script chat cam setup is the key to any successful webcam site. Whether you’re going small or going big, the right technology will make you a sensation. Explore Scrile Stream to build a fully branded, revenue-capable webcam chat site built to succeed in 2026 and beyond.
FAQ – Script Chat Cam (Webcam Site Scripts, Tokens, PPM, Moderation)
Helpful answers for founders comparing cam chat scripts in 2026: what features matter, how monetization works, and when it’s time to go custom.
What is a “script chat cam” solution?
▾
A script chat cam solution is a ready-made (or semi-ready) software package for launching a webcam platform: live video, interactive chat, user accounts, performer tools, and admin management in one system.
The real value isn’t just “streaming works.” It’s the business layer: billing, tokens/tips, private sessions, moderation, reporting, and a performer dashboard that people will actually use.
What features should a good cam chat script include in 2026?
▾
At minimum: stable live streaming, low-latency chat, private chat modes, a strong performer dashboard, and an admin panel with moderation and user management.
For revenue: tokens/tips/gifts, pay-per-minute (PPM), paid messages, and clear analytics (conversion, ARPPU, retention, top rooms, payout reporting). “Extra monetization” is no longer extra — it’s the core product.
Tokens vs pay-per-minute: which monetization model is better?
▾
Tokens are great for engagement: users tip, send gifts, unlock actions, and spend in small bursts. This creates more “participation” and can lift revenue per session.
PPM is great for clarity: a private session runs on time, pricing is obvious, and billing is predictable. Many successful platforms combine both: tokens for public interaction + PPM for premium 1:1/private experiences.
Do I need WordPress to run a webcam site script?
▾
Not necessarily. Some scripts integrate with WordPress for faster setup, but that also means your performance and security depend on plugins, themes, and ongoing updates.
If you plan to scale or build a unique UX, a standalone product (or custom build) is usually cleaner: fewer moving parts, fewer “plugin conflicts,” and more control over streaming, billing, and moderation workflows.
What payment options should a cam platform support?
▾
A strong setup typically includes card payments (via adult-friendly processors where needed), token wallets, and flexible pricing rules (PPM, paid messages, gifts, subscriptions, bundles).
Also check the “business plumbing”: chargeback handling, payout logic for performers/studios, taxes/fees visibility, and fraud controls. Monetization isn’t just a button — it’s a system you’ll run every day.
What moderation and safety tools are “must-have” today?
▾
At minimum: user reporting, ban/mute tools, room moderation, keyword filters, and clear admin roles. If you run public rooms, you need fast response tools — not “we’ll review later” buttons.
For compliance, many platforms add age gating, performer verification workflows, audit logs, and content policy enforcement. The goal is simple: protect your performers, protect users, and protect the business.
How do I evaluate streaming quality and scalability in a cam script?
▾
Ask how the platform handles peak traffic, multi-stream rooms, and mobile performance. “It works in a demo” is not the same as “it works when 500 viewers join at once.”
Look for adaptive bitrate, stability under poor networks, and an architecture that supports horizontal scaling. Also check operational basics: monitoring, logs, backups, and upgrade strategy (because your site will evolve constantly).
Can I migrate from a cheap script to a better platform later?
▾
Yes, but migrations hurt if you don’t plan for them. The hard part is not the UI — it’s users, wallets/tokens, performer payouts, media assets, and preserving SEO and login flows.
If you know you’ll scale, start with clean data models and export options. Even if you launch fast, make sure you’re not locking yourself into a system that can’t be upgraded without losing revenue or trust.
Plug-and-play script vs custom development: when should I choose each?
▾
Plug-and-play is best when you need speed and your business model is standard. You can validate demand, test traffic sources, and learn what users actually want without a big build.
Custom development makes sense when your platform is the business asset: unique UX, studio workflows, deeper monetization (tokens + PPM + paid messages + affiliates), higher performance needs, and full ownership with no vendor lock-in.
What is the fastest way to launch a cam platform without sacrificing long-term growth?
▾
Launch with the core loop first: stable live streaming, chat, billing, and a performer dashboard. Then add the revenue multipliers: tokens/gifts, private sessions, paid messages, and an affiliate program.
The smartest “fast” approach is choosing a foundation that can evolve. If the initial system can’t scale or can’t be customized, you’ll pay later in rework, migrations, and lost momentum.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
You’re juggling five chats, a dozen emails, and three notifications that say “Just following up :)” — all before noon. That’s the chaos most people live in, and it’s exactly why AI respond to text tools have exploded in 2026. People don’t just want help writing. They want smart replies that feel like them, sent in seconds.
Fast isn’t enough anymore. The tone has to be right. The reply has to make sense. And it better not sound like a robot or a broken copy-paste.
That’s where AI comes in — not to flood inboxes with generic messages, but to help you respond like a human, faster than humanly possible.
In this article, we’re looking at five of the best tools on the market. They’re not just clever — they’re useful. They help you reply faster, better, and with less mental load. And if you’re building something bigger? We’ve got something for that, too.
AI Respond to Text — 2026 Quick Comparison
| Tool | Core Use Case | Biggest Strengths | Key Limitations | Integrations / Workflow | Pricing Snapshot* | Best For |
|---|
| Typli.ai | Fast, polished replies for email/DMs | Tone presets; quick edits; good for paste-in → reply | No live chat threads; no native messaging/scheduling | Copy/paste into inboxes; pairs with long-form writing | Freemium; paid unlocks unlimited & advanced | Solo founders, marketers, creators juggling many convos |
| AIFreeBox | One-off, no-login reply generation | 100% free; instant browser use; multiple tones | No memory/history; no integrations; not for ongoing chats | Ad-hoc web usage only | Free | Casual users, micro-biz owners testing styles |
| ChatGPT (custom GPT) | Build a tailored reply assistant | Highly customizable tone & rules; can learn your FAQs | Setup takes time; no native inbox integrations; not realtime by default | Embed via apps/zaps; use inside email/chat as helper | ChatGPT Plus for builder ($) | Creators/consultants/devs needing bespoke behavior |
| Reply.io | Sales outreach & inbound handling at scale | Detects intent; suggests stage-aware replies; CRM sync | Overkill for individuals; B2B focus; not for NSFW/fan DMs | Deep with HubSpot/Salesforce & sequences | Business tiers only | SDR teams, founders running campaigns |
| Jasper AI Chat | Brand-consistent replies & longer responses | Brand Voice memory; pulls from style guides/content | No direct inbox integrations; premium pricing | Content workflows; copy/paste into channels | Premium plans | Brand managers, creators needing consistent tone |
| Scrile AI (custom build) | Your own white-label reply system | Full control: tone, rules, NSFW filters, pay-per-reply, gateways | Requires a custom dev engagement | Integrates with your CRM, payments, apps; owns data | Project-based | Platforms, creators & startups needing branded, monetized chat |
*Indicative only; vendors change tiers often.
Why People Use AI to Respond to Texts Now

Nobody wants to spend their day typing the same sentence twenty different ways. “Thanks for your message!” turns into a full-time job when you’re managing clients, fans, or customers across platforms. That’s the whole point of using AI message reply tools — they shave hours off your week and take the edge off decision fatigue.
People aren’t just tired of typing; they’re also under pressure from rising expectations. Modern messaging benchmarks are brutal: people expect a response almost immediately, even if your team is offline. As Infobip notes in their guide on automated SMS replies:
“Customers expect near-instant replies. Automated responses meet that demand and show you’re available, outside business hours.”
— Infobip
That’s exactly where AI respond-to-text tools shine. They let you acknowledge every message, keep conversations warm, and protect your sanity — without forcing you to be glued to your screen 24/7.
But it’s not just about speed. It’s about how you sound. The way you reply defines your tone, your brand, even your income if you’re working in a chat-based business. A rushed answer can sound cold. An overlong one looks fake. AI tools can adjust that — they know when to be warm, when to be short, when to add a wink or keep it formal.
For adult content creators, NSFW chat hosts, and online coaches, this isn’t optional — it’s survival. You’re expected to respond like you’re always present. AI that responds to texts fills the gap, handling common replies or smoothing out the awkward pauses without breaking the illusion of live interaction. It’s also becoming a quiet backbone of customer support, especially for solo founders or indie operators running lean.
What you’re doing in those DMs, inboxes, or fan chats is very close to what big brands do with AI support agents. Salesforce describes these AI helpers in a way that maps perfectly to the tools you’re reviewing here:
“AI customer service agents are software programs that use artificial intelligence to interact with customers, providing automated responses to common queries,”
— Salesforce
In other words, whether you’re running fan chats, premium DMs, or lean customer support, you’re building your own version of an AI service agent. The only real difference is how much tone, logic, and monetization control you demand from your tools.
The real shift? You’re not just automating messages — you’re automating tone, energy, and attention. AI doesn’t just send a reply. It protects your bandwidth so you can focus where it counts.
That’s why people are leaning hard into this tech — not just to save time, but to stay sharp, stay personal, and stay scalable. If you’re looking for an AI reply to messages, a smarter AI response to text messages, or even a playful AI text reply tool to match your style, you’re not alone. The demand’s massive — and in the next section, you’ll see the tools leading the charge.
5 Best AI Reply Tools in 2026
Whether you’re managing fans, clients, or customers, the ability to respond quickly — without sounding robotic — is now a competitive edge. The best AI respond to text tools in 2026 don’t just spit out phrases. They get your tone, context, and intent. Let’s break down five top contenders, each with their own strengths and blind spots.
Typli.ai — Speed Meets Smart Tone

Typli.ai is more than a writing assistant — it’s built for fast, polished replies across email, social DMs, and text-based communication. Just paste an incoming message, choose a style, and Typli generates a ready-to-send reply in seconds.
Best for: Marketers, creators, and solo founders who juggle dozens of conversations daily.
Pros:
- Tone presets from formal to casual to bold
- Edits replies for clarity and impact
- Works for emails, chats, and social posts
- Seamless long-form writing integration
Cons:
- Not ideal for live chat or conversational threads
- No built-in messaging integrations
- Lacks automation or scheduling features
Pricing: Freemium with paid tiers for unlimited generations and advanced options.
AIFreeBox — Free-Use Tools with No Login Hassle
AIFreeBox offers lightweight AI responders you can use instantly — no setup, no subscription. It’s perfect when you just want to generate a quick, thoughtful reply without opening a full app.
Best for: Casual users, small business owners, or creators testing tone and style variations.
Pros:
- 100% free and browser-based
- Multiple tone options for replies
- No sign-up or installation required
- Useful for short replies and email copy
Cons:
- No memory or chat history
- Can’t integrate into real workflows
- Not suitable for ongoing customer conversations
Pricing: Completely free.
ChatGPT — Personalized AI Reply Bots on Demand

If you’re already using ChatGPT, building a custom GPT for replies is a powerful option. OpenAI now allows users to create GPT-powered bots that can be trained on specific tone, style, or even customer service flows. This makes it a favorite among tech-savvy creators, startup founders, and anyone who needs an AI reply to messages that actually reflects their voice.
You can design a reply assistant that understands your tone, your context, and your audience — whether you’re chatting with clients or managing a community. Custom instructions let you train it on FAQs, preferred phrases, and even rules for what not to say.
Best for: Creators, consultants, and developers who want to fully tailor how their replies sound and behave.
Pros:
- Fully customizable AI behavior and tone
- Can be trained on your data and rules
- Works across email, chat, or internal platforms
- Option to build NSFW or niche support bots
Cons:
- Requires some technical skill or patience to set up
- No native messaging integrations (you’ll need to embed it elsewhere)
- Doesn’t handle real-time conversations out of the box
Pricing: Included with ChatGPT Plus ($20/mo) for GPT builder access.
Reply.io — AI Outreach and Smart Replies for Sales Teams
Reply.io isn’t built for fans or DMs — it’s built for outreach. But its smart reply handling is one of the most effective use cases for AI in B2B. Sales teams use it to automate and personalize responses to inbound messages, especially when scaling cold outreach or follow-ups. It uses AI to scan incoming replies and then suggest context-aware responses based on the conversation stage.
It’s not a one-message-at-a-time tool. It’s a system for ai response to text messages at scale — great for founders, SDRs, and sales-focused businesses who want to manage replies without losing the human touch.
Best for: Sales and lead-gen teams managing dozens or hundreds of conversations at once.
Pros:
- Detects lead intent and prioritizes hot replies
- Suggests smart responses based on context
- Supports outreach campaigns and workflows
- Integrates with CRMs like HubSpot and Salesforce
Cons:
- Overkill for individual creators or casual use
- UX is designed for teams, not solo operators
- Not built for NSFW or fan-based chat use
Pricing: Paid tiers only, geared toward business users and sales orgs.
Jasper AI Chat — Brand-Consistent Replies for Busy Creators
Jasper started as a content creation tool, but its AI chat module has quietly become one of the smartest options for personalized message replies — especially for businesses that care about tone and brand voice. You can train Jasper to match your writing style, use custom knowledge, and respond with a tone that feels like you — whether you’re sending a client update or replying to a fan.
Its strength lies in consistency. If you’re running a content-heavy operation or managing multiple channels, Jasper helps keep your tone aligned without sounding repetitive or forced. It’s not just an ai text reply generator — it’s a brand-safe assistant that keeps your communication sharp.
Best for: Creators, marketers, and brand managers who want replies that align with their voice, tone, and messaging.
Pros:
- Customizable voice presets and memory
- Pulls from your brand style or previous content
- Great for long-form responses or thoughtful replies
- Includes workflows for campaigns, emails, and chats
Cons:
- Less useful for live, short-form chat or NSFW
- No direct message integrations — you’ll copy/paste replies
- Premium pricing may be too much for casual use
Pricing: Premium only, with plans tailored toward marketers and business creators.
Create Your Own AI That Responds to Text with Scrile AI
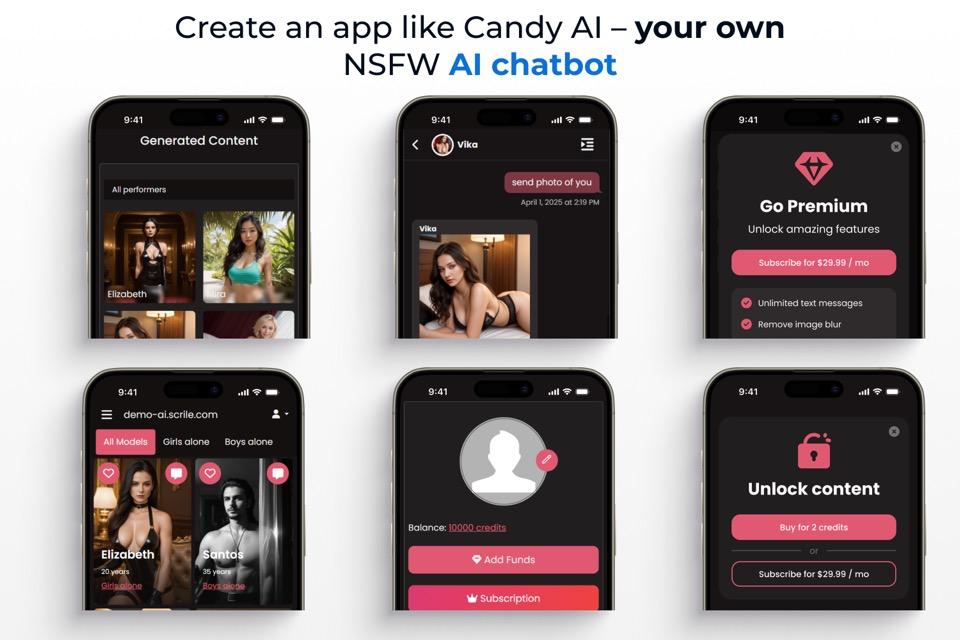
Sometimes, none of the existing tools are enough. You don’t just want quick replies — you want control. You want a chat app that speaks in your voice, reacts on your terms, and earns money while it does. That’s where Scrile AI comes in. It’s not a SaaS tool. It’s a white-label development partner that builds custom AI chat solutions tailored to your brand, your model, and your audience.
Unlike off-the-shelf reply tools, Scrile AI lets you define how your AI respond to text engine works. Want emotional tone shifts? You got it. Want NSFW filters and pay-per-reply logic? Done. You’re not stuck in someone else’s interface — you’re building your own.
Scrile AI is built to support:
- Adult content creators running pay-per-message NSFW chats
- Dating coaches offering roleplay training bots
- OnlyFans-style businesses with custom tip-to-unlock responses
- Therapy and mental health startups building AI journaling companions
- Customer support teams who need branded bots that follow strict tone guidelines
- Creators and influencers monetizing private conversations or content unlocks
You decide how messages are generated, what tone they carry, and what rules they follow. Want to integrate your own payment gateway? Use your own dataset? Add custom onboarding logic or tiered response behavior? Scrile AI doesn’t just allow that — it’s built for it.
Your community, your business, your flow — powered by AI that responds to text, your way. When you’re done testing generic tools, Scrile helps you build the real thing.
Conclusion – Better Replies, Built Smarter
AI tools that reply for you aren’t just novelties anymore — they’re part of how business gets done. From inboxes to DMs, people expect speed, clarity, and a response that sounds like a real human. The right AI respond to text tool can save time, keep your tone consistent, and scale your communication without burning you out.
That’s not just a feeling — it’s backed by adoption numbers. A recent guide on customer service auto-replies cites data from Heymarket showing how widespread automated responses already are in business messaging.
“In fact, 89% of businesses use auto-replies to manage customer expectations, and tailored messages significantly enhance engagement.”
— Sobot, “50 Automatic Reply Customer Service Examples”
When almost nine out of ten businesses rely on auto-replies, the real differentiator isn’t whether you automate — it’s how smart and on-brand those replies feel. That’s where the tools in this list — and especially a custom Scrile AI setup — turn basic automation into a real competitive edge.
But automation only goes so far when you’re boxed into someone else’s design. What happens when you need replies that reflect your brand, your tone, or even your industry rules? That’s where control matters more than convenience.
Scrile AI gives you that control. You don’t get a basic chatbot. You get your own branded reply system — custom logic, tone presets, monetization tools, and even NSFW capability if that’s your space. No limits. No cookie-cutter templates. Just an engine that responds exactly how you want it to.
So if you’re done testing generic tools and ready to build something that’s truly yours, contact the Scrile AI team today and start building your AI respond to text solution from the ground up.
FAQ – AI Respond to Text (Reply Tools, Auto Replies & Custom Bots)
What does “AI respond to text” actually mean in 2026?
“AI respond to text” usually means tools that generate a ready-to-send reply from an incoming message. You paste a text/email/DM, pick a tone (friendly, formal, flirty, direct), and the AI drafts a response that matches your intent.
The big upgrade in 2026 is tone + context. People don’t just want speed — they want replies that sound human, match the conversation, and don’t feel like obvious automation.
What’s the difference between an AI reply tool and an auto-reply template?
Templates are fixed text. They’re fast, but they can’t adapt to the message you received, and they often feel cold or repetitive when used too often.
AI reply tools generate a response based on the actual content and your chosen tone. That means you can stay consistent while still sounding personal, even when you’re replying to dozens of similar messages per day.
Which AI reply tool is “best” for most people?
“Best” depends on your workflow. If you want quick, polished replies with minimal setup, lightweight reply generators are usually enough. If you want a reply assistant that follows your rules, voice, and FAQs, a customizable assistant is a better fit.
A simple test: paste three real messages (short, emotional, and complicated), then check which tool keeps the meaning while matching your tone. The winner is the one that needs the fewest edits before you hit send.
Can AI respond to SMS, WhatsApp, Instagram DMs, or Telegram messages automatically?
Some tools work only in “copy/paste” mode (you generate a reply and send it yourself). Full automation usually requires integrations — for example, connecting your inbox or chat platform through APIs, bots, or automation tools.
If your goal is true auto-replies in real time, you’ll want a setup that can read incoming messages, classify intent, and send approved responses — with guardrails so the AI doesn’t go off-script.
How do I make AI replies sound like me (and not like a robot)?
Give the AI a short “voice guide”: how you greet people, how formal you are, how long replies should be, and what you never say. Add 3–5 examples of real replies you wrote and ask the tool to follow that pattern.
Then lock a consistent structure: one-line acknowledgement + one helpful point + a clear next step. This makes replies feel human, even when they’re generated quickly.
Is it safe to paste private messages into AI reply tools?
Treat it like any third-party service. Before using a tool for sensitive chats, check whether it stores messages, how long it retains them, and whether you can delete your data. If those details are unclear, don’t paste confidential content.
A safer habit is to remove personal identifiers, use placeholders, and keep your “business rules” (prices, policies, FAQs) in a separate reference doc instead of sharing full conversations.
What are the biggest limitations of AI response tools?
The most common issues are missing context, tone mismatch, and “confident but wrong” replies. AI can also over-explain simple situations or sound too enthusiastic in serious conversations.
That’s why the best workflows keep a human in the loop for high-stakes messages, and reserve automation for repeated scenarios (common questions, scheduling, status updates, first responses, and follow-ups).
Can AI reply tools help with sales and lead qualification?
Yes — when replies are stage-aware. Good tools can generate short responses that ask the right question, confirm details, and move the lead forward without sounding pushy.
The key is consistency: define what qualifies a lead, what info you need (budget, timeline, goal), and what your “next step” should be (call link, demo request, or a short intake form).
When does it make sense to build your own AI that responds to texts?
Build your own system when messaging is part of your product or revenue model — for example, a branded chat experience, paid replies, tiered access, or strict rules around tone and content.
A custom build also matters when you need integrations (CRM, payments, user accounts, analytics) and want control over data, moderation, and how the assistant behaves across different user segments.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
If you’re here for long narrative roleplay, deep characters, and stories that don’t forget what happened 20 messages ago — you’re not alone. In 2026, “creative writing AI” isn’t just about drafting paragraphs. It’s about continuity: consistent character voice, remembered relationships, stable lore, and scene-to-scene logic.
This guide is updated for the queries people actually search: the best AI chatbot for creative writing, the best AI for interactive stories with continuity, and the best AI roleplay apps for long narrative story writing with good memory (2026). We’ll cover fiction-first writing tools, roleplay-focused chat apps, and power-user setups (lorebooks / story bibles) — plus what to choose if your top priority is tone matching and in-context rewriting.
Quick tip: if your main use case is emotional prose and “human” dialogue, jump to Claude. If your priority is memory-driven roleplay continuity, go to the roleplay section.
The creative process isn’t disappearing — it’s just getting an upgrade. In 2026, writers aren’t fighting against AI; they’re collaborating with it. From novelists and screenwriters to indie creators and poets, more people are using intelligent tools to get unstuck, find their voice, or spin ideas into something usable.
What used to take hours — refining tone, rewriting awkward dialogue, brainstorming an opening line — now takes minutes. The best AI for creative writing doesn’t replace your voice. It supports it. It can suggest a line that sounds more like your character, help you experiment with mood, or reshape a meandering scene into something that actually flows.
Some apps are built for structured storytelling. Others shine when you need loose, wild ideation. And a few are surprisingly good at understanding nuance — emotional subtext, pacing, rhythm. The question isn’t “Should I use AI to write?” It’s “Which tool is worth it?”
This article breaks down the top creative writing AI apps in 2026 — who they’re for, what they’re good at, and where they might fall short. And if you’re a founder, ghostwriter, or fiction entrepreneur looking to build something custom? We’ll also show how Scrile AI can help you create your own writing assistant from scratch — trained on your tone, built for your audience, and ready to scale.
Best AI Apps for Creative Writing
| Tool | Best for | Memory / continuity support | Strongest creative use case | Main limitation |
|---|
| Sudowrite | Fiction drafting and scene expansion | Project and story-structure support | Novel scenes, sensory detail, “show don’t tell,” plot brainstorming | Can produce cliché prose without strong guidance |
| Claude | Nuanced prose and emotional dialogue | Strong current-context handling, depending on plan/model | Voice-sensitive rewriting, internal monologue, sensitive scenes | No fiction-specific planning UI |
| NovelAI | Interactive fiction and long story sessions | Memory and lorebook-style workflow | Fanfiction, RPG-style adventures, genre fiction | Requires setup to keep canon clean |
| SillyTavern | Power-user roleplay control | World Info / lorebooks | Long-running roleplay with stable world rules | Not a simple one-click writing app |
| Novelcrafter | Story bible and series consistency | Codex / story bible system | Series, worldbuilding, continuity-heavy fiction | More system than instant text generator |
| Jasper | Creative + marketing hybrid writing | Brand voice, not story canon | Blurbs, descriptions, sales copy, author marketing | Not ideal for scene continuation |
| Notion AI | Turning notes and outlines into drafts | Workspace context, not deep fiction memory | Organized writers already using Notion | Limited for long narrative continuity |
| Scrile AI | Custom creative AI platform | Custom memory and character logic can be designed | Monetized AI character, writing, roleplay, or creator platforms | Requires custom implementation, not a self-serve writing app |
What Makes an AI Tool Creative?

Not all writing AIs are built the same. Some are glorified autocomplete engines — great for product descriptions or blog intros, but hopeless when it comes to writing a scene that actually feels like something. Creative writing is a different animal entirely. It’s about style, rhythm, character, emotional flow — not just spitting out grammatically correct sentences.
The best AI for creative writing in 2026 doesn’t just write quickly. It writes with voice. That means adjusting tone, mimicking a character’s perspective, or reworking a paragraph so it feels right, even if it breaks the rules of formal grammar.
Modern tools like Claude have gotten significantly better at this. Thanks to bigger context windows (they can now “remember” more of what you’ve written), they can track plot arcs, personalities, and pacing. Some even let you lock in a character’s tone so it stays consistent across a whole conversation or story.
There’s also training. Tools like Sudowrite are fine-tuned on fiction. That means they know how to finish a short story, or rewrite a flat sentence into something with texture. For example, say you’ve written a line of dialogue that sounds like it came from a tax attorney. You can ask the AI to rewrite it so it sounds like a stoned bartender in a beach town — and it’ll probably nail it.
These aren’t generic chatbots anymore. They’re semi-coherent, style-aware co-writers. Some can shift tone between paragraphs. Others specialize in world-building or emotional dialogue. And the best ones give you just enough structure to avoid chaos — while still leaving room for the weird, human part of storytelling to shine.
That’s what makes them creative. Not perfection. Possibility.
Best AI Creative Writing Tools by Workflow
There’s no shortage of AI tools out there — but when it comes to actual creativity, only a few are worth your time. Below, we’ve rounded up eight of the best AI for creative writing apps in 2026. Each one brings something different to the table, whether you’re drafting fiction, brainstorming ideas, or rewriting a scene that just isn’t landing.
For fiction drafting and prose improvement
Sudowrite, Claude, Lex, Rytr
For creative + marketing hybrid workflows
Jasper, Copy.ai, Notion AI, Writesonic
For roleplay, fanfiction, and interactive story continuity
NovelAI, Kindroid, SillyTavern, Novelcrafter
For building a monetized creative writing AI platform
Scrile AI
Sudowrite – The Fiction Writer’s Secret Weapon

Who it’s for: Novelists, short story writers, fanfiction authors, or anyone writing narrative fiction
Sudowrite was built from the ground up for fiction writers. Unlike more generalized tools, it doesn’t just spit out ad copy or SEO blurbs — it actually knows how to build scenes, mimic character voices, and help you write prose that doesn’t sound robotic.
Its standout feature is “Story Engine,” a tool that lets you build characters, plan arcs, and write chapters while the AI keeps track of everything. You can feed it a paragraph and ask for sensory details, alternative dialogue, or even emotional tweaks. Stuck on a scene? It’ll help finish it in your tone. Want to rewrite a flat sentence? It’ll offer five options — including one that’s “more poetic” and one that’s “weirder.”
It also remembers long chunks of story, thanks to its larger context window. That means your character doesn’t suddenly change tone halfway through a scene.
Strengths:
– Designed specifically for fiction
– Flexible tone rewriting
– Excellent “Show, don’t tell” assistant
– Unique brainstorming tools like “wormhole” and “twist”
Flaws:
– Slight learning curve if you’re new to AI writing
– Sometimes outputs cliché or overly safe phrasing
Why it stands out:
Sudowrite feels like it was built by fiction writers for fiction writers. It doesn’t try to take over your story — it gives you better options when you’re stuck and lets you stay in control of your voice.
Jasper AI – Blending Creativity with Content Strategy
Who it’s for: Writers who juggle creative content and business writing, or need flexible tone-shifting
Jasper AI has long been a go-to for marketers and content teams, but it’s also surprisingly useful for creatives — especially those working across genres or formats. Its tone control tools are solid, and its built-in templates offer everything from story hooks to social-friendly blurbs.
It shines in hybrid creative workflows. If you’re writing a novel and need to build a back-cover description, Jasper can help. Need a scene rephrased in a sarcastic or romantic tone? Jasper handles that too. And if you’re writing for clients — say, ghostwriting steamy fiction while also managing their email list — this tool adapts fast.
The interface is clean and quick to navigate. Plus, Jasper’s “brand voice” settings let you train it on your style, which makes it much more useful for serialized or long-form writing.
Strengths:
– Tone flexibility across formats
– Solid at story starters and hooks
– Brand voice customization works well
Flaws:
– Not fiction-specific; less helpful for scene continuation
– Gets stiff or formal if you don’t guide it well
Why it stands out:
Jasper hits a rare middle ground: creative, but grounded. It’s one of the best AI for creative writing if your work blends storytelling, marketing, and the occasional splash of poetry.
Claude – Emotionally Fluent and Surprisingly Human
Who it’s for: Writers who care about nuance, emotional tone, and narrative flow
Anthropic’s Claude has emerged as a favorite among writers who need more than just competent text — they want their AI to actually “get” human emotion. And Claude does. Compared to more assertive, high-energy tools, Claude’s responses feel calm, deliberate, and often startlingly insightful.
This makes it especially good for creative writing. Claude is strong at continuing a narrative in the same voice, rewriting paragraphs with a softer or more dramatic tone, and understanding subtext in dialogue. It’s ideal for writers crafting sensitive character moments, emotionally complex scenes, or internal monologues.
Claude’s longer context window also helps — it can “remember” much more of your work as you write, allowing it to stay consistent over several pages. You can feed it an entire chapter and ask for notes, edits, or alternate takes on key scenes.
Strengths:
– Natural, emotionally intelligent language
– Excellent for tone matching and dialogue
– Long-form consistency
Flaws:
– Doesn’t come with a built-in UI — best used through third-party tools or dev setups
– Occasionally too passive or cautious in suggestions
Why it stands out:
Claude is less flashy than other tools, but it’s one of the best AI for creative writing if your work leans on subtlety, sensitivity, and strong voice control. It feels more like a writing partner than a machine.
Copy.ai – Fast, Flexible, and Idea-Driven
Who it’s for: Creators juggling copy and creativity — social writers, short story dabblers, content marketers with a narrative streak
Copy.ai is known for fast content generation, but that doesn’t mean it can’t be creative. If you’re looking for a tool that can help spark story ideas, reframe a scene in a punchier way, or turn a vague prompt into something usable, this one’s surprisingly versatile.
Its real strength lies in short-form ideation. Writers use Copy.ai to brainstorm story titles, pitch concepts, rewrite blurbs, or turn journal entries into structured scenes. While it isn’t purpose-built for fiction, it works well as a drafting assistant — especially in early-stage idea development or voice experimentation.
The interface is clean and fast, and it lets you shift tone easily. You can also train it slightly by feeding previous writing samples or using its prompt enhancer feature.
Strengths:
– Great for brainstorming and quick rewrites
– Easy to use for multi-format writing
– Good tone-shifting tools
Flaws:
– Not ideal for long-form or full-scene continuity
– Lacks the depth fiction writers may want for arcs or dialogue
Why it stands out:
Copy.ai is one of the best AI for creative writing if you’re early in your process or looking to keep your writing fresh. It won’t finish your novel — but it might help you finally start it.
Notion AI – From Notes to Drafts in One Click
Who it’s for: Creative thinkers who work in outlines, notes, or scattered ideas
Notion AI isn’t a traditional writing app — and that’s what makes it useful. Built into the broader Notion workspace, it’s perfect for writers who brainstorm in chunks: notes, bullet points, scene fragments, character boards. It helps bridge the gap between scattered ideas and something resembling a real draft.
You can highlight a messy block of text and ask Notion AI to rework it into paragraphs. Or give it a prompt like “turn this list into a poetic description” — and it often surprises you. It’s especially useful for those who plot stories in Notion already, or use it as a second brain for creative projects.
That said, Notion AI is still limited. It’s not optimized for story arcs or tone consistency across scenes. But for what it does — fast, flexible synthesis of messy notes — it’s genuinely helpful.
Strengths:
– Perfect for idea-to-draft conversion
– Feels natural for Notion users already organizing their writing
– Handles tone changes well within a short form
Flaws:
– Not built for deep narrative or long-form fiction
– Limited memory and continuity between prompts
Why it stands out:
If your creative process lives inside Notion, this is a no-brainer. Notion AI is one of the best AI for creative writing if you’re constantly jumping between outlines, dialogue sketches, and half-formed ideas.
Rytr – Budget-Friendly and Surprisingly Capable
Who it’s for: Writers on a tight budget who still want creative support
Rytr doesn’t make headlines, but it punches above its weight for the price. For under $10/month, you get a clean interface, tone customization, and a solid variety of use cases — including storytelling, poetry, and creative descriptions.
It’s especially good for early drafts. You give it a short prompt or a few bullet points, and Rytr spins it into something usable. It won’t nail complex arcs or subtle character beats, but it’s great at rewording, summarizing, or throwing out ideas when you’re blocked.
The tone controls are easy to use — and surprisingly specific. You can request “humorous,” “convincing,” or “narrative” tones and watch your writing shift accordingly. It’s ideal for short stories, content blurbs, or even RPG world-building prompts.
Strengths:
– Very affordable
– Great for short creative tasks
– Clean and simple interface
Flaws:
– Struggles with long-form or layered scenes
– Occasionally generic without strong prompts
Why it stands out:
Rytr is one of the best AI for creative writing if you’re on a budget and want help generating or reshaping content. It’s not fancy — but it gets the job done better than you’d expect.
Writesonic (Chatsonic) – Experimental and Versatile

Who it’s for: Writers who like to test tone, remix style, or push genre boundaries
Writesonic’s Chatsonic feature is one of the more flexible AI tools out there. It’s a conversational interface like ChatGPT, but with real-time web access (optional), built-in personas, and plenty of voice-shifting options. If you’re the kind of writer who likes to say “give me a weird version of this paragraph” or “rewrite this as if it’s narrated by a washed-up detective,” Chatsonic will actually try.
It supports long-form writing reasonably well — not at the level of Sudowrite or Claude, but better than most generic bots. And it’s fun to experiment with. Whether you’re drafting strange genre crossovers, writing fiction for newsletters, or testing tone for character dialogue, it gives you options that feel fresh.
Its free tier is limited, and the interface can be busy. But if you’re a flexible, idea-driven writer who thrives on prompts, this tool can unlock unexpected directions.
Strengths:
– Highly experimental
– Great at voice play and tone shifts
– Option for web-connected generation
Flaws:
– UX can be overwhelming
– Requires strong prompting for best results
Why it stands out:
Chatsonic is one of the best AI for creative writing if you want to push boundaries or just see what happens when you let the AI get weird. It’s not polished — but that’s kind of the point.
Lex.page – Minimalist Writing, Maximum Focus
Who it’s for: Writers who hate clutter and just want to write
Lex isn’t trying to be everything. It’s a distraction-free writing space with built-in AI features that actually feel helpful. The interface is bare bones — like Google Docs stripped down to its essentials — and that’s exactly what makes it work for creatives.
The AI works in-context. You can ask it to finish your sentence, generate alternative phrasings, or even pitch better transitions. It’s not trying to manage your story arc or world-building. It’s just there to help you move forward when you stall.
Lex shines in the early and mid stages of writing — when you’re putting down messy ideas and want help sharpening them up. It’s not for outlining or planning. It’s for writing.
Strengths:
– Minimal UI, fast workflow
– Great for polishing drafts without overcomplicating them
– In-line suggestions feel natural
Flaws:
– Lacks structure or creative templates
– Not suitable for complex fiction building
Why it stands out:
Lex is one of the best AI for creative writing if you just want a clean, focused place to write — with a little AI support when you need it, and silence when you don’t.
Why Some Writers Still Build Their Own Tools

Even with all the polished AI tools on the market, not every writer finds what they need out of the box. That’s especially true for creators working in niche genres, serialized fiction, interactive storytelling, or erotica — where tone, format, and audience expectations often push the limits of what standard AI writing tools are built for.
Sometimes it’s less about what a tool can do, and more about what it doesn’t let you control. Want your AI to write in your exact tone? That’s tough without training a model on your own writing. Want a chatbot that responds like your character would? Good luck customizing that deeply with most commercial tools. What if you need a place to host fan-written stories behind a paywall, or build an AI editor that gives scene-level feedback based on your specific narrative style?
That’s where custom AI comes in — and more writers are realizing they don’t have to wait for someone else to build it.
Indie creators, ghostwriters, digital publishers, and even roleplay game writers are quietly hiring developers to build tools that match their vision. Some want an AI writing assistant trained on their past work. Others want full platforms — complete with subscription monetization, user-generated content tools, or AI character bots. Some even want “closed-loop” systems: tools that write, edit, publish, and track engagement, all under one roof.
It’s not about ditching the creative process. It’s about designing tools that fit into your workflow, your market, and your voice — instead of forcing yourself to adapt to a tool made for someone else’s goals.
And if you’re serious about that route, building from scratch isn’t as wild (or expensive) as it used to be. That’s where Scrile AI comes in. Let’s talk about that.
Memory, Continuity, and Why Stories Break
When people search for “best AI for interactive stories (continuity)” they usually mean one thing: the story stops behaving like a story. Names change. Relationships reset. A character forgets a defining event.
In practice, there are three different “memory” layers:
1) Context window (what the model can see right now)
2) Long-term memory (saved facts recalled later)
3) Lorebooks / story bibles (structured canon injected when relevant)
If your priority is deep roleplay with long narrative arcs, choose tools that give you long-term memory or lorebook-style controls — not just a generic text generator.
NovelAI — Built for Interactive Stories and Continuity
Who it’s for: Writers who want interactive storytelling, branching scenes, and better continuity across long narrative sessions
NovelAI is one of the most “story-native” options when your goal is not a polished marketing paragraph, but a living narrative that keeps its own logic. The big advantage is how it treats memory: you can keep important story facts consistently visible to the model, so characters don’t randomly change motivation mid-arc.
If you write fanfiction, RPG-style adventures, or serialized chapters, NovelAI’s workflow feels closer to “writing inside a story engine” than chatting with a generic bot. It’s especially useful when you want the AI to keep returning to the same canon details, relationships, and world rules without re-explaining everything each time.
Strengths:
– Great for interactive stories and long narrative flow
– Memory-style controls help reduce continuity drift
– Strong for genre fiction, fanfiction, and RPG writing
Flaws:
– Not the best choice for “brand voice” marketing workflows
– Requires a bit of setup to get the most from memory/lore
Why it stands out:
NovelAI is one of the best AI tools for interactive stories in 2026 if continuity matters more than corporate polish.
Kindroid — Roleplay Chat with Long-Term Memory for Deep Characters
Who it’s for: Roleplay writers who want deep characters, evolving relationships, and long narrative continuity
If your core query is “best AI roleplay apps for long narrative story writing (good memory)”, this is the type of tool you’re actually looking for. Kindroid is built around layered memory systems designed to preserve important details over time, so your character can stay consistent across weeks of story progression.
This makes it a strong pick for ongoing roleplay, character-driven interactive fiction, and romance/relationship arcs where small details matter. Instead of constantly re-feeding context, you build a stable base (backstory, key memories, journal-style entries) and let the conversation evolve.
Strengths:
– Designed for ongoing character continuity
– Long-term memory approach helps maintain “who the character is”
– Great for relationship arcs and long-running stories
Flaws:
– Less ideal for structured “novel drafting” workflows
– Best results often depend on how well you set up the memory inputs
Why it stands out:
Kindroid fits the 2026 “memory-first” roleplay use case better than most general writing apps.
SillyTavern — Power-User Roleplay Setup with Lorebooks (World Info)
Who it’s for: Advanced roleplay writers who want maximum control over lore, character rules, and continuity
SillyTavern isn’t “one AI model”. It’s a roleplay-focused interface that lets you build story structure around your chats. The key feature for long narrative continuity is World Info (also called lorebooks/memory books): you store canon facts, character rules, locations, and recurring details, and the system injects them when relevant — so the AI doesn’t drift as easily.
This is the kind of setup people use when they’re serious about deep characters, consistent worldbuilding, and long-form interactive storytelling — especially if they’ve outgrown simple chat apps.
Strengths:
– Lorebook/World Info system improves continuity
– Highly customizable roleplay workflow
– Great for long-running stories with stable canon
Flaws:
– Setup time (it’s not a “one-click app”)
– More moving parts than a typical chatbot
Why it stands out:
If continuity is your #1 pain, a lorebook-based workflow is often the most reliable fix.
Novelcrafter — A Story Bible (Codex) That Keeps Your World Consistent
Who it’s for: Novelists and fanfiction writers who need a story bible to prevent continuity errors
Novelcrafter is less about “generate a paragraph” and more about building a durable writing system. Its Codex works like an intelligent story bible: characters, locations, plot threads, and progressions stay organized so you can keep a series consistent across chapters.
For long-form fiction (especially series and fanfiction), this is a big deal: continuity breaks happen when your world knowledge is scattered. A story bible workflow reduces that friction — and makes it easier to feed consistent context into your writing process.
Strengths:
– Strong story bible / worldbuilding organization
– Great for long projects and series continuity
– Helps reduce character/lore drift over time
Flaws:
– Learning curve compared to simple tools
– More “system” than “instant chatbot”
Why it stands out:
If your creative writing pain is continuity, a dedicated story bible tool beats generic note apps.
Build a Custom Creative Writing AI App with Scrile AI
Most off-the-shelf writing tools are designed to be one-size-fits-all. That’s great for convenience — until you realize that convenience comes at the cost of flexibility, control, and long-term growth. If you’re serious about building a creative writing product that does more than generate text, you need something that’s yours from the ground up.
That’s where Scrile AI comes in. It’s not a plug-and-play app. It’s a full-scale custom development partner for founders, publishers, and creators who want to launch unique AI-powered platforms tailored to their voice, workflow, and audience.
Let’s say you’re a fiction writer with a massive back catalog and want to turn your style into an AI co-writer. Or you’re a digital publisher looking to build a platform for serialized fiction, complete with reader interaction, content controls, and pay-per-story monetization. Scrile can build that — and much more.
Here’s what Scrile AI can help you create:
- AI writing assistants with memory, tone control, and plot-awareness
- Character development tools trained on your world and lore
- Interactive storytelling apps with reader input or chatbot-style narration
- Monetized platforms for creators, featuring subscriptions, tips, or affiliate links
- NSFW-friendly tools for erotica writers, adult publishers, or fantasy roleplay
- Teacher or tutor tools for creative writing courses with AI feedback built in
Unlike generic SaaS tools, Scrile’s solutions are:
- Fully branded — your name, your domain, your UI
- Data-private — you control the training data and who sees it
- Legally yours — no terms of service conflicts when it comes to AI-generated content
- Flexible for growth — built to scale, integrate, and monetize however you want
Whether you’re a solo author building a writing assistant, or a startup launching the next Wattpad-style platform, Scrile AI brings the backend muscle and frontend polish to help you launch fast — and scale with confidence.
And yes, that includes romance, smut, fanfiction, or whatever other genre mainstream tools tend to shy away from.
If you’ve ever thought, “I wish there was a tool that did this,” Scrile can help you build it.
Conclusion
Creative writing isn’t going anywhere — it’s just evolving alongside the tools we use. The rise of AI hasn’t made writers obsolete. If anything, it’s given them new ways to work, experiment, and push past creative blocks. Whether you’re crafting novels, building fanfiction communities, or scripting interactive stories, the right AI can enhance your process without taking it over.
Tools like Claude, Jasper, and Sudowrite are already helping thousands of writers draft faster and rewrite smarter. But if you’re dreaming bigger — building your own platform, shaping AI in your voice, or monetizing a writing app that doesn’t exist yet — it might be time to go custom.
That’s where Scrile AI comes in. It’s not just another writing tool. It’s your development team for building something original. Explore what Scrile AI can help you create — and turn your creative vision into a working, scalable product.
FAQ – Best AI for Creative Writing (2026)
What is the best AI for creative writing in 2026?
“Best” depends on what you mean by creative writing. If you want voice control and emotionally consistent scenes, tools that behave like a writing partner tend to win. If you want fast drafting and clean rewrites for mixed creative + marketing work, “structured” writing tools often feel smoother.
A simple way to choose is to test the same scene in 2–3 tools: one dialogue-heavy, one descriptive, and one with a tricky tonal shift. The best option is the one that keeps your intent without flattening your style.
What’s the difference between an AI writing app and a roleplay/story engine?
Writing apps are usually designed for producing text outputs: drafts, rewrites, outlines, summaries, and edits. They’re great when you’re “authoring” something and want control over structure and clarity.
Story engines and roleplay-style chat apps are built for ongoing narrative flow. They often feel more like interactive fiction: you steer the scene in real time, and the tool tries to maintain character behavior, relationships, and continuity across many messages.
Which AI is best for long interactive stories with continuity?
For long, interactive storytelling, continuity matters more than “pretty paragraphs.” Look for tools that support memory features, lorebooks, or a story-bible workflow—anything that prevents the AI from forgetting names, timelines, and relationship dynamics.
If you’re writing serialized chapters, RPG campaigns, or fanfiction arcs, pick a tool that lets you keep canon facts “always visible” to the model. That single feature often beats raw model quality in real-world long sessions.
How does “memory” work in creative writing AI tools?
Most “memory” is really three layers: the current context (what the model can see right now), saved long-term facts (character notes, preferences, relationships), and structured canon (lorebooks/story bibles injected when relevant).
When stories break, it’s usually because the canon lives only in your head or scattered notes. A memory-friendly workflow keeps key facts in one place and re-feeds them consistently, so the AI doesn’t drift or reset the scene logic mid-arc.
How do I make the AI match my character voice and tone?
Give the AI a short “voice sheet”: a paragraph describing the character’s worldview, a few signature phrases, what they never say, and a tiny sample of dialogue in your preferred style. Voice control improves fast when the rules are specific.
Also feed it the last 1–2 turns of your best writing and ask for continuation “in the same cadence.” If the tool keeps sounding generic, tighten constraints: fewer adjectives, shorter sentences, or a fixed point-of-view rule.
Can AI help with worldbuilding without contradicting my canon?
Yes—if you treat canon like a database. Keep a compact “world rules” doc: geography, factions, magic/tech limits, timeline anchors, and character relationships. Then instruct the AI to propose ideas that must obey those rules.
A good pattern is: ask for 10 options, then force the AI to “self-check” each one against your rules and flag contradictions. This produces fewer flashy surprises, but far fewer continuity disasters.
What’s the best workflow for fanfiction, roleplay, or RPG-style writing?
Fanfiction and RPG writing usually fail at the same spot: the AI forgets the “fixed” universe facts. The solution is a lorebook or story bible that stores canon details (character traits, relationships, locations, recurring items) and injects them when relevant.
Start small: 20–40 canon facts beats a 20-page encyclopedia. Then expand only when you see repeated drift (names, timeline, motivations). Your lore should grow from real failure points, not from perfectionism.
Is it safe to paste my unpublished manuscript into AI tools?
Treat it like any third-party platform: read the privacy policy, retention rules, and whether your data can be used to improve models. If you can’t clearly find those answers, don’t paste your most sensitive material.
A safer compromise is to share only what the AI needs: a scene excerpt instead of the whole chapter, placeholder names for sensitive details, and a separate “canon summary” you control and can reuse across tools.
Will AI-generated text cause plagiarism or copyright issues?
AI can accidentally produce familiar phrasing—especially if you ask it to imitate a specific author too closely. The practical rule is: use AI for drafts and exploration, then revise with your own voice and do a final originality check if you publish commercially.
If you’re building a business workflow, prefer tools and prompts that focus on your unique style guide (your characters, your lore, your tone constraints). That reduces “generic internet echo” and makes the output more reliably yours.
When does it make sense to build a custom creative writing AI app?
If writing is your product (not just your hobby), custom starts to make sense. That includes roleplay platforms, interactive fiction apps, fan communities, and tools that monetize premium stories, characters, or creator-owned worlds.
A custom build lets you control the UI, safety rules, monetization, and memory system—so your users aren’t stuck with a generic chatbot that forgets canon every 20 messages.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
Back in the early days of remote work, hosting a virtual event meant firing up Zoom, sending out a calendar invite, and hoping everyone showed up. But by 2026, that’s ancient history. Virtual events have become a core part of how we work, teach, promote, and connect. From small workshops with niche audiences to international symposiums featuring hundreds of speakers, the demand for professional, reliable, and feature-rich solutions has exploded.
We’re not just talking about video streams anymore. Modern virtual conference platforms offer a full ecosystem: interactive stages, live chat, networking lounges, sponsor booths, analytics dashboards, and even AI-powered recommendations. Hosting a standout online event now means delivering real engagement and value—not just replicating a meeting in digital form.
Virtual conferences aren’t just a temporary trend from the lockdown era anymore. PR and communications teams now treat online events as one of their main ways to reach audiences. As Reena Aggarwal notes in Agility PR Solutions:
Virtual events deliver faster reach, greater flexibility, and deeper impact—all this with lower costs and in minimal time.
When you’re choosing a virtual conference platform, you’re effectively choosing the infrastructure for that reach, flexibility, and impact. That’s why this comparison focuses so much on reliability, engagement tools, and how well each solution scales with your plans.
Here’s the challenge: the number of tools available has grown just as fast as the events themselves. Some are sleek and easy to use but lack customization. Others offer deep features but require technical skills or large budgets. That’s why this virtual conference platform comparison exists—to help you figure out which platforms are worth your time (and your budget), depending on the type of event you’re planning.
In this guide, we’ll walk through the 10 best virtual conference platform comparison in 2026, highlight their unique strengths, and help you narrow down what works best for your audience, goals, and team size. Whether you’re hosting a virtual summit, an educational forum, or a full-blown branded expo, the right platform can transform your event from functional to unforgettable.
What Makes a Platform Best for Hosting a Conference?

Let’s be honest: you’re not just looking for a place to throw up a Zoom link and pray for engagement. In 2026, expectations for online events are high—and attendees can spot a lazy setup from a mile away. So, what separates decent conference hosting platforms from the ones that actually make people stick around, interact, and remember your event?
First and foremost: reliability. If your keynote speaker freezes mid-sentence or the stream dies during the Q&A, it’s game over. The best platforms for virtual conferences are built to handle high traffic, international time zones, and real-time interactions—without buckling under pressure.
Then there’s flexibility. You might be planning a tight, single-track symposium with a few dozen attendees—or a sprawling virtual expo with breakout rooms, sponsor booths, and overlapping sessions. The top platforms let you scale up or down, add modules, and switch formats without rebuilding the whole thing from scratch.
Let’s talk engagement. Chat boxes are great, but they’re just the start. You want tools that mimic the spontaneous hallway conversation: live polls, virtual networking tables, direct messaging, even speed-meeting functions. If people don’t interact, they don’t stay.
Don’t forget branding. Slapping your logo on a landing page doesn’t count. You want to build an experience that reflects your identity—from the lobby design to button colors. A good platform should make your event feel like yours, not a template.
And finally: analytics. It’s not just about who showed up—it’s about how they moved through your event. What they clicked, how long they watched, where they dropped off. Smart tracking helps you understand what worked and what didn’t—and do better next time.
In short: virtual conferences platforms need more than just video. They need structure, personality, and room to grow.
Quick Comparison of the 10 Best Virtual Conference Platforms
| Platform | Best For | Key Strengths | Limitations | Pricing (est.) |
|---|
| Zoom Events | Large-scale, hybrid events | Reliability, enterprise trust, multi-track support | Limited customization, corporate feel | From $1,500/yr |
| Hopin (RingCentral Events) | Sponsor-heavy, interactive summits | Networking, expo zones, Q&A, booths | Complex dashboard, steep pricing | $800–$1,000/event |
| SpotMe | Corporate & medical conferences | Compliance, multilingual, mobile apps | Best for enterprise, less for casual events | Custom pricing |
| Webex Events (Socio) | Enterprises, global teams | Branding, scalability, gamification | Costly, enterprise-focused | Custom pricing |
| Airmeet | Community-driven workshops | Virtual tables, networking, ease of use | Less formal, fewer sponsor features | From $200/mo |
| BigMarker | Marketers & B2B lead gen | CRM/email integration, automation | Less “flashy,” more functional | $99–$500/mo |
| vFairs | Virtual expos & trade shows | 3D lobbies, booths, sponsor showcase | Steep setup, long learning curve | Custom pricing |
| HeySummit | Small, niche events | Easy to launch, simple ticketing | Not scalable for large expos | From $29/mo |
| ON24 | Enterprise marketing & demand gen | Deep analytics, CRM integrations | Expensive, steep learning | From $500/mo |
| Run The World | Casual, interactive gatherings | Mobile-first, fun, speed networking | Light on customization | From $99/mo |
1. Zoom Events
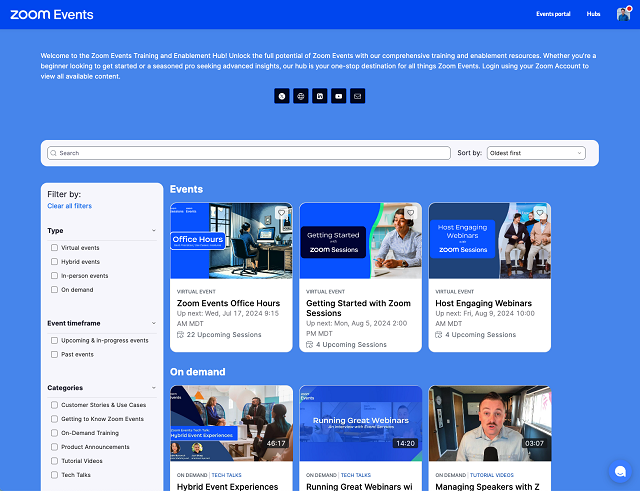
Zoom’s event platform is built for scale. It takes what people already trust from regular Zoom and expands it into a system for large, organized virtual gatherings. It’s designed to handle everything from webinars and town halls to full-scale conferences.
With support for tens of thousands of attendees, Zoom Events offers multi-track agendas, ticketing, sponsor integration, and backstage access for presenters. It’s a strong option among conference hosting platforms, especially for enterprises that already use Zoom in-house.
Where it really works is hybrid events. If you’re combining a physical venue with a remote audience, this platform offers a reliable bridge between the two.
That positioning isn’t just marketing copy. In its hybrid events research, Zoom highlights how much event teams now rely on hybrid formats to extend reach and prove ROI:
Hybrid events offer event marketers a variety of benefits that include expanding their reach to a larger audience, lower costs, and greater access to data
For organizers, that reinforces why hybrid-ready infrastructure in Zoom Events matters so much: registration flows, backstage tools, analytics, and networking all feed into a single event story. If your roadmap includes more complex hybrid conferences, that data layer becomes just as important as video quality.
Downsides? Limited customization and a UI that still feels very “corporate.” Also, it’s not cheap—plans often start around $1,500/year and scale up based on your needs.
If you’re comparing tools in a serious virtual conference platform comparison, Zoom Events deserves a spot on the shortlist—for scale and reliability alone.
2. Hopin (Now RingCentral Events)
Hopin was built for events first—making it one of the more advanced virtual conferences platforms on the market. After merging into RingCentral Events, it’s still focused on recreating the energy of in-person events, but online.
Its key strength is interactivity: live stages, virtual booths, sponsor zones, 1:1 networking tools, and audience Q&A. It’s an especially good fit for marketing summits, product launches, and fast-paced events where interaction matters.
However, all that power comes with complexity. Hopin can feel bloated if you’re running something small or simple. The dashboard takes time to learn, and pricing can quickly escalate—reports suggest it starts around $800–$1,000 per event.
If you’re shopping around for a virtual summit platforms solution with room for sponsors and audience engagement, Hopin holds up. But it’s best suited for teams that have the time (and people) to manage its advanced features.
3. SpotMe
SpotMe isn’t trying to be everything for everyone. Instead, it doubles down on what it does best: high-touch, professional events—especially in corporate, pharmaceutical, and B2B spaces. It’s trusted by Fortune 500 companies and global medical brands, and for good reason.
The platform delivers real-time audience engagement features like polls, quizzes, personalized agendas, and breakout rooms—all wrapped in a clean, brandable interface. One standout is its support for fully customizable mobile apps, letting attendees carry the full event in their pocket.
SpotMe really shines in settings that require compliance, privacy, and content control—like medical conferences and investor summits. It also supports multilingual delivery, which is essential for global audiences.
If you’re comparing tools specifically for virtual symposium platforms, SpotMe makes a strong case. It’s serious, secure, and designed to support events where the smallest detail can’t be left to chance.
4. Webex Events (formerly Socio)
Webex Events comes from Cisco’s enterprise-grade ecosystem, and it brings that same polished feel to the event space. This is a platform built for scalability, professional branding, and complex agendas—perfect for when reliability matters more than flash.
What sets Webex Events apart in 2026 is how well it blends flexibility with structure. You can design multi-track events with detailed sponsor sections, in-depth analytics, and even gamification features—all without needing a dev team.
Custom branding is central. From pre-event pages to post-event surveys, you can shape the experience to reflect your organization’s tone and style. Sponsor booths, attendee networking, and live engagement tools round out the package.
Among the many virtual summit platforms, Webex Events holds its ground as a top-tier option—especially for enterprise organizations and global teams with complex needs. It’s not the cheapest, but it delivers on professionalism and scale.
5. Airmeet
If your event thrives on conversation, not just content, Airmeet is one to watch. Built for community-driven experiences, it emphasizes interaction over presentation. It’s ideal for workshops, education sessions, bootcamps, and any event where attendees want to meet, not just watch.
Airmeet’s virtual “tables” create space for networking, casual chats, or breakout workgroups. Speed networking, emoji reactions, and host controls make the experience feel less like a broadcast and more like a real event.
For organizers, setup is relatively easy. You can brand the event space, configure sessions, and even run ticketing without outside tools.
Among today’s virtual conference hosting services, Airmeet stands out for making events feel human—even through a screen. It’s less suited for rigid, formal conferences but shines when your audience wants to connect and collaborate.
6. BigMarker
BigMarker walks the line between webinar software and full-blown event platform. It’s ideal for marketers who want to turn webinars, demos, and online conferences into lead-generating machines.
At its core, BigMarker combines video hosting with marketing automation. You get features like built-in landing pages, email funnels, CRM integrations, and branded registration flows. That makes it a smart pick for companies running multiple small-to-medium events throughout the year.
Use cases range from training sessions to product launches and customer education events. Unlike some platforms that focus only on the attendee experience, BigMarker gives equal attention to the behind-the-scenes workflows—so your team can promote, manage, and follow up without jumping between tools.
While it may not be the flashiest on the market, it’s reliable and purpose-built for B2B marketers who need results, not just viewers. It’s a solid option in any serious virtual conference platform comparison, especially for lead-focused teams.
7. vFairs
vFairs is built for virtual trade shows, expos, and career fairs—any event that relies heavily on booths, branding, and lots of concurrent conversations. It’s highly visual, with 3D lobbies, interactive exhibit halls, and customizable avatars that make the experience feel more like a digital venue than a basic webinar tool.
What sets it apart is the flexibility in design. You can replicate a branded convention center, organize content by theme, and give sponsors plenty of space to shine. Attendees can browse booths, download resources, chat with reps, and schedule follow-ups—all in one interface.
That said, it comes with complexity. Setup time is longer, and there’s a learning curve for new organizers. But if visual impact matters and your audience expects a “wow” factor, vFairs delivers.
Among conference hosting platforms, vFairs is an excellent fit for large, content-heavy events where first impressions—and sponsor impressions—really count.
8. HeySummit
HeySummit doesn’t try to be the biggest. Instead, it’s built for creators, coaches, and solo professionals running small, highly targeted online summits. If you’re running a niche event with a few guest speakers, gated content, and live or pre-recorded sessions, this platform gets the job done—without the bulk.
Its strength lies in simplicity. The interface is clean, the speaker onboarding is smooth, and it handles things like ticketing, registration pages, and session scheduling out of the box. You won’t need to patch together multiple services just to go live.
The platform is best for lightweight operations—people who care more about launching quickly and managing a focused audience than building an elaborate expo. Among virtual conferences platforms, it’s one of the easiest to start with, especially if you’re a team of one.
It won’t scale to massive multi-track summits, but for small events with clear messaging and a loyal following, HeySummit is more than enough.
9. ON24
ON24 is one of the few platforms on this list that was built with enterprise marketing in mind. It’s not just about hosting events—it’s about converting attendees into customers and nurturing those leads long after the webinar ends.
The platform excels in analytics and content lifecycle tools. It tracks how users interact with every part of your event—clicks, downloads, questions, poll responses—and rolls that data into your CRM or marketing automation system. For companies focused on demand generation, ON24 is a powerhouse.
It’s best suited for enterprises running multiple campaigns and needing clear ROI. With its branded experiences, always-on content hubs, and multi-session events, it works well for both live and on-demand events.
In virtual conference platform comparison, ON24 stands out for large organizations that need rich data, integration with existing tech stacks, and serious lead-gen capabilities.
10. Run The World
If most platforms feel like enterprise software, Run The World feels like a social app that hosts events. It’s light, fast to launch, and geared toward casual, high-energy gatherings like interactive panels, community chats, or expert roundtables.
The interface is fun, mobile-first, and made for audience participation. Features like cocktail-style speed networking, reactions, and co-hosted sessions help make virtual events feel less lonely—and more alive.
It’s especially popular among creators, thought leaders, and startups looking to run polished events without a huge learning curve. You won’t get complex sponsor zones or deep customization, but that’s not the point. Run The World delivers simplicity and interaction, not enterprise depth.
If your priority is speed, ease, and energy—and your event leans more toward conversation than keynote lectures—Run The World makes sense. It’s not for every use case, but in the right hands, it turns virtual conferences platforms into something genuinely engaging.
Need Something More Tailored? A Custom-Built Alternative from Scrile Meet
Even with all the polished platforms on the market, not every use case fits neatly into a pre-built box. For some businesses—especially those in consulting, coaching, healthcare, education, and wellness—the off-the-shelf tools feel either too bloated or too limited. They need something else: ownership, control, and the ability to build exactly what fits their audience.
That pressure to “get it exactly right” exists because virtual events are no longer side projects. As event specialists at EventBuilder put it:
In summary: They’re now a staple in the event planner’s toolkit, offering a unique blend of accessibility, engagement, and measurable results.
If virtual conferences are becoming a staple in your own toolkit, it often makes sense to own the underlying platform. That’s where a solution like Scrile Meet stands out: instead of renting generic event software, you’re investing in a branded system that can evolve with your format and business model.
That’s where Scrile Meet steps in. Unlike most SaaS options, this is a turnkey software solution that lets you launch your own fully branded virtual consultation platform—no coding needed, and no platform commissions cutting into your revenue. You get the infrastructure, the features, and the design flexibility—all under your control.
Here’s what it includes:
- Private video calls, both one-on-one and group sessions
- Appointment booking with calendar integration
- Paid access to sessions or messaging
- A built-in admin dashboard to manage users, payments, and analytics
- Fully customizable UI/UX so your platform matches your brand from day one
There’s no need for downloads or native apps—it runs right in the browser and works across all devices. And crucially, your data stays yours. That’s a big deal in industries where privacy and control really matter.
Whether you’re a coach running premium sessions, a legal consultant managing client calls, or a niche educator looking to monetize expertise, Scrile Meet offers a way to own the platform instead of renting space on someone else’s.
It’s not another app—it’s the framework to build your own. If you’re thinking long-term, this isn’t just a smarter move—it’s a future-proof one.
Off-the-Shelf Platforms vs. Scrile Meet
| Option | Ownership | Branding | Features | Pricing Model | Weak Points |
|---|
| Zoom, Hopin, vFairs, etc. | Vendor-owned | Limited customization | Multi-track, sponsor zones | Subscription / per-event fee | Commission cuts, vendor lock-in |
| Lightweight Tools (HeySummit, Run The World) | Vendor-owned | Basic branding | Ticketing, live sessions | Low monthly fee | Limited scale, no deep customization |
| Scrile Meet (Custom Platform) | Full client ownership | 100% custom UI/UX | Video calls, booking, payments, analytics | One-time license + optional support | None — turnkey handled by Scrile |
How to Choose the Right Virtual Conference Platform
There’s no universal “best” tool—only the one that fits your goals. Before you commit to anything, ask yourself:
- Are you hosting a free event, or selling tickets?
- Will you need expo booths, sponsor zones, or just a few speakers and Q&As?
- Is branding a priority, or are you fine with a generic look?
- How tech-savvy is your team—and your audience?
This guide’s virtual conference platform comparison should help you match your needs to the right tools. Platforms like HeySummit work for lean solo events, while Hopin or vFairs cater to big-budget, multi-track expos. Meanwhile, if none of them give you full ownership or flexibility, building your own platform (like with Scrile Meet) might be the right path forward.
Conclusion
Choosing the right tool sets the tone for your entire event. With virtual conference platforms evolving fast, it’s smart to think ahead—not just about your next event, but the next five.
Test a few, ask for demos, explore what’s out there—and if nothing fits, consider building your own. A fully branded platform like Scrile Meet gives you long-term control, monetization options, and freedom from third-party limits.
Use this virtual conference platform comparison as your starting point, and create something that actually reflects your vision.
FAQ – Virtual Conference Platform Comparison (Summits, Expos, Hybrid Events)
Quick, practical answers for choosing the right platform in 2026: reliability, engagement tools, sponsor features, branding, and analytics.
What is a virtual conference platform (and how is it different from Zoom meetings)?
▾
A virtual conference platform is a full event ecosystem, not just video calls. It combines live stages, multi-track agendas, registration/ticketing, networking, sponsor areas, chat/Q&A, and post-event analytics in one place.
If your event has multiple sessions, sponsors, lead capture, or serious branding needs, you’ll quickly hit the limits of “just send a Zoom link.” Conference platforms are built for structure, scale, and measurable outcomes.
What features matter most when comparing virtual conference platforms?
▾
Start with reliability (stable streaming + capacity), then flexibility (multi-track, breakout rooms, session formats), and engagement (polls, Q&A, networking, direct messages). These are the “make or break” items.
Next comes branding (custom lobby/landing pages, your domain, emails) and analytics (session watch time, drop-offs, clicks, sponsor ROI). The best platform is the one that fits your event format and goals—not the one with the longest feature list.
What’s best for a virtual summit vs a workshop vs a virtual expo?
▾
Summits usually need multi-track agendas, speaker management, sponsor zones, and strong attendee networking. Workshops need interactive rooms, small-group experiences, and “human” engagement tools.
Expos and trade shows need booths, lead capture, downloadable resources, sponsor showcase areas, and a venue-like UI. Pick a platform that matches your event’s center of gravity: content, community, or sponsors.
How should I compare pricing (per event vs per month vs custom)?
▾
Pricing isn’t just “the plan.” It’s the limits attached to the plan: attendee caps, streaming hours, number of sessions, recording storage, branding level, and support. Some platforms look cheap until you add the features you actually need.
A smart comparison is total event cost: platform fee + integrations + production + support time. If your team is small, “simple and reliable” often beats “powerful but complex.”
What should I look for if I’m hosting a hybrid event?
▾
Hybrid events need “two audiences, one story.” You want strong registration flows, multi-track agendas, speaker/backstage tools, and stable streaming for remote attendees—plus analytics that prove ROI.
Also check how the platform handles replays, on-demand libraries, and engagement for remote attendees (polls, Q&A, networking). Hybrid fails when remote users feel like second-class attendees.
How do sponsor booths and lead generation work on these platforms?
▾
Sponsor tools usually include virtual booths, downloadable resources, CTA buttons, meeting booking, and chat with reps. The best platforms turn sponsor exposure into measurable actions, not just “logo placement.”
If sponsorship is a core revenue stream, prioritize platforms with built-in lead capture, CRM integrations, and sponsor analytics (booth visits, clicks, downloads, meetings). That’s how you justify pricing and renew sponsors next time.
What engagement features actually keep attendees active?
▾
The basics are chat, polls, and Q&A. The difference-makers are networking tables, 1:1 matchmaking, speed meetings, and direct messaging—features that recreate hallway conversations.
A good platform makes interaction easy and “low friction.” If networking takes five clicks and a tutorial, most people won’t do it. Your best engagement tool is simplicity.
How important are branding and white-label options for conferences?
▾
Branding matters more than people expect. If the event feels like a generic template, your content has to work twice as hard to feel premium. Strong platforms let you control lobby design, registration pages, emails, colors, and sometimes even UI layout.
White-label is especially valuable when events are part of your business model (series, membership community, paid summits). It builds long-term trust and makes each event feel like a continuation of your brand—not a one-off tool.
What analytics should I track to prove event ROI?
▾
Track the funnel: registrations → attendance → session engagement → actions (poll answers, Q&A, downloads, booth visits, meetings booked). These show whether people actually participated, not just “showed up.”
For sponsors, measure booth traffic, clicks, downloads, and meetings. For content, measure watch time per session and drop-off points. Great analytics help you improve the next event instead of guessing.
When should I build a custom virtual conference platform instead of using SaaS?
▾
Go SaaS when you need speed and your format is standard. Go custom when events are core to your business and you need full control: branding, user flows, access rules, monetization, deep integrations, or a unique attendee experience.
Custom also makes sense when you want to own the roadmap and data, avoid vendor limits, and turn events into a scalable product (series, paid community, sponsor ecosystem). That’s where a tailored build (like a custom alternative mentioned in your article) becomes a real business asset.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.
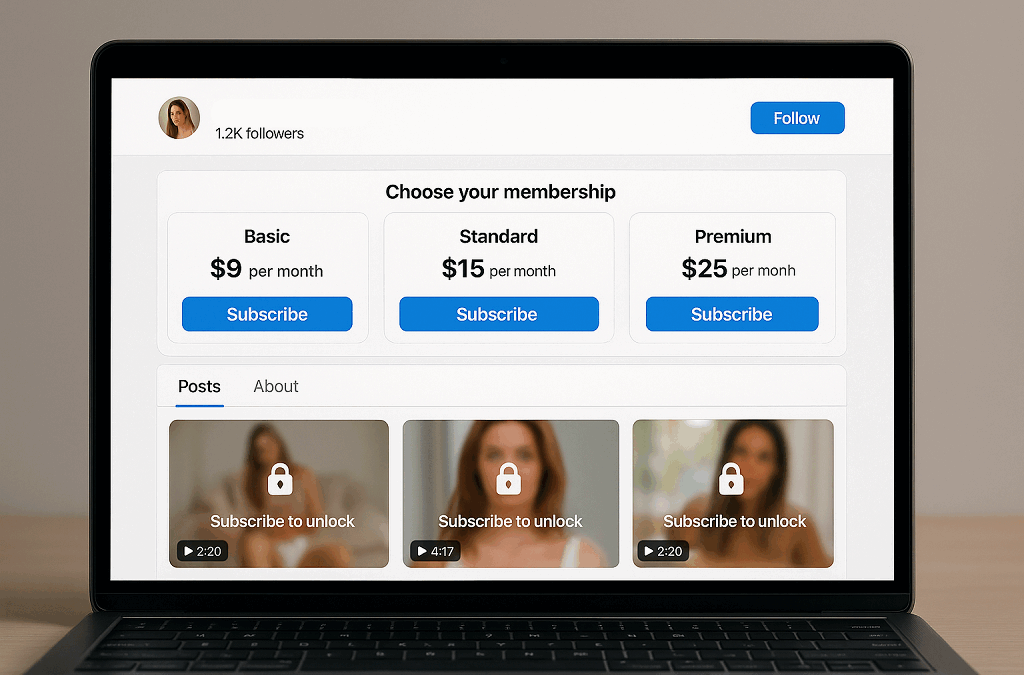
by Polina Yan
The subscription content economy is exploding. Creators are earning serious money, and fans are paying for access, not ads. It’s a shift in how content is valued — and who controls the revenue.
An OnlyFans clone isn’t a knockoff. It’s a self-owned, custom-built version of the same monetization model: monthly subscriptions, pay-per-view drops, tipping, private messages — but all under your branding. You keep 100% of what you earn. Platforms can’t ban you overnight. Your visibility doesn’t depend on algorithms.
This model works especially well in adult content, where mainstream platforms still refuse to support creators openly. But it’s also growing into adjacent spaces: fitness, coaching, fandoms — and now, the adult NFT marketplace. Tokenized content and gated drops are finding a home inside clone platforms built for flexibility.
2026 isn’t just a good time to launch. It’s the right time. The infrastructure is there. The demand is there. What’s missing is your own name on the door.
Let’s walk through how to build your own platform — and why 2026 might be the best time to do it.
Don’t Just Copy: Understand Why OnlyFans Took Off

OnlyFans didn’t go viral because of some flashy UI. It exploded because it gave creators power. They set the price, controlled the content, and got paid directly — no middlemen, no censors, no platforms pulling the plug.
The rise of OnlyFans wasn’t accidental. It matched a cultural shift: people were ready to pay for access. Real access. Unfiltered, direct, often NSFW. Fans didn’t want mass-produced, ad-funded content anymore. They wanted something personal. And they were happy to tip for it.
An OnlyFans clone needs to capture that same logic — not just clone the layout. Behind every feature is a reason it works:
- Subscriptions reward consistency
- Tips reward moments of connection
- PPV messages unlock curiosity
- Anonymity removes friction
- Exclusivity fuels retention
According to Influencer Marketing Factory report, the creator economy crossed $21 billion in revenue in 2023 — and that’s just reported income. Much of it came from platforms that embraced fan-funded content instead of fighting it.
So before you start hunting for OnlyFans clone scripts or rushing into design mockups, zoom out. Ask why this model worked in the first place. And how your platform can do it better — for your niche, your audience, and your brand.
Cloning success means cloning strategy — not just software.
Core Features You’ll Need — No Fluff
When building an OnlyFans clone, you don’t need gimmicks. You need fundamentals that work, scale, and keep both creators and fans active. Many clones fail because they either overload the site with features nobody uses or ignore the backend that makes things stable. Your goal should be to build something lean, secure, and efficient from day one.
Here’s a breakdown of the non-negotiable core features:
- Subscription tiers — Flexible pricing options let creators offer entry-level access, premium exclusives, and VIP perks. This boosts retention and gives fans choices that match their budget.
- Creator dashboards — Let creators manage content, track earnings, schedule posts, and set custom pricing without jumping through hoops.
- Payout systems — Timely, transparent, and multi-currency payment support is critical. If creators can’t get paid easily, they won’t stick around.
- Messaging and media locking — Direct DMs, pay-to-unlock messages, locked photo galleries, and video paywalls are must-haves for monetization and engagement.
- Tipping and pay-per-view — Fans love spontaneous support. A tip jar, reaction buttons, or one-time paid content helps creators make more from every interaction.
- Live streaming — Live video isn’t optional anymore. Streamed events, private calls, or group shows give creators a way to connect and earn in real time.
- Mobile-first UX — Most users will access your site via phone. The interface has to feel smooth, responsive, and intuitive on any screen size.
- Security and moderation tools — Include ID checks, content watermarks, age verification, and built-in moderation controls to avoid legal risks and protect creators.
You’re not just serving one user group. Creators need autonomy over their work, while fans need seamless access and payment options. If your site frustrates either side, you’ll lose both. Balance matters. Prioritize usability, speed, and reliability before even thinking about advanced features.
Revenue Streams to Stack

An OnlyFans clone that depends on subscriptions alone is leaving money on the table. Subscriptions are your foundation, but serious income comes from everything built around them. When creators have multiple ways to earn, retention goes up — and so does average revenue per user.
An OnlyFans-style platform only works when subscriptions are just the entry point, not the whole business model. Analysts looking at OnlyFans itself keep stressing that its power comes from combining multiple revenue mechanics, not relying on a single paywall.
“OnlyFans has matured into a global case study in how creators monetize attention. Subscriptions, PPV, bundles, and collabs form the commercial engine”
— Influencer Marketing Hub, “The Monetization Mechanics of OnlyFans”
When you design your clone, treat this as a blueprint. The more intelligently you combine subscriptions, PPV, bundles, and collabs for your niche, the more resilient and scalable your revenue stack becomes.
Let’s break down the essential revenue streams you need to bake into your build from day one:
- Pay-per-view content (PPV): One-time unlocks for premium videos or photos. Great for new followers who aren’t ready to commit to a monthly fee.
- Bundles and collections: Let fans buy sets of content at a discount. This works especially well for themed drops or behind-the-scenes series.
- Tip-to-unlock media: Hidden messages, special content, or reactions that only show after a tip. Adds exclusivity and gives fans a reason to engage.
- Private messaging fees: Charge per message or open up VIP inbox access for top-tier fans. Direct interaction is the number one reason many fans pay.
- Referral incentives: Reward users who bring in new subscribers. This builds loyalty and turns fans into brand promoters.
- Live streaming with paid interactions: Let creators stream directly from their dashboard and charge for live shoutouts, private moments, or interactive games.
- NFT content licensing: This is growing fast in the adult nft marketplace. Selling NFT-tagged videos or images with proof of ownership gives creators new monetization angles — and fans something rare to own.
- Smart contracts for royalties: Especially with NFT content, smart contracts allow creators to earn every time their work is resold or licensed.
A clone that supports all these isn’t just modern — it’s future-proof. And if you’re launching in 2026, you should be aiming for that kind of edge.
Clone Scripts vs Custom Builds

Let’s get one thing straight: a clone script is not the same as a real business infrastructure. It’s a shortcut — a prebuilt chunk of code designed to mimic another platform’s functionality, usually for a low price and with minimal effort. Most OnlyFans clones you see out there? Scripts. And while they look good on day one, the cracks show fast.
At first, a script might seem like a smart move. Fast launch, low cost, plug-and-play interface. But once creators start uploading content, fans begin subscribing, and money starts flowing — things change. Performance issues pop up. Customization hits a wall. Security gets shaky. You realize you’re stuck with someone else’s backend logic, and the only way out is a rebuild.
Why Scripts Break Under Pressure
Scalability is usually the first casualty. Scripts aren’t built for real traffic. A few thousand users can turn your site into a lagging mess. Branding is another major roadblock — try turning a cookie-cutter layout into something people remember. You won’t. And then there’s the legal headache: some clone scripts lift code too literally from the source, putting you at risk the moment lawyers start looking.
The truth is, building a lasting Only Fans clone means investing in a system that can evolve. One you can fully own, expand, and control — from payment logic to user flow. Not one that locks you into someone else’s limitations. If your business model is serious, your tech stack has to be too.
You’re not here to mimic but to monetize. And scripts don’t build sustainable ecosystems — they build headaches disguised as platforms.
Get Clear on Niche and Brand

Every successful OnlyFans clone starts with one thing — focus. Pick a clear audience and design every part of your site around them. Don’t aim wide. Aim deep. A strong niche builds stronger loyalty than a generic “all-creators-welcome” approach.
Some of the most active segments today include:
- Couples creating interactive content together
- Fetish communities looking for secure, custom content access
- Fitness creators offering exclusive plans and live coaching
- Cosplayers blending fan service with exclusive behind-the-scenes clips
Your niche defines your identity. Use it to shape your branding, tone, and feature set. Choose colors, language, and layouts that resonate with the people you want to attract.
Trust follows clarity. If users feel like the platform reflects their world, they’ll stick around. That applies to both fans and creators.
Plenty of OnlyFans clones launched without direction and vanished. One fitness-creator-focused clone tried pivoting into crypto, then gaming, then dating — and lost its core base in the process.
Don’t build something for “everyone.” Build something real for a community that needs it.
That’s exactly how sustainable creator businesses grow: not by trying to please everyone, but by serving a very specific group extraordinarily well. One of the earliest people to articulate this mindset for creators was writer and editor Kevin Kelly.
“To be a successful creator you don’t need millions.”
— Kevin Kelly, “1,000 True Fans”
An OnlyFans clone works on the same principle. If your platform helps a focused group of creators earn well from their true fans, you don’t need mass-market scale to build a serious business.
Compliance, Privacy, and Payouts

If you’re building an OnlyFans clone, legal and financial compliance isn’t something to figure out later. It’s baked into the foundation from day one.
Start with age verification. For adult platforms, this isn’t optional — it’s the law. Use trusted age-check providers and make sure content uploads follow 2257 record-keeping requirements. If you skip this, you’re one flagged video away from getting booted off your host.
Tax compliance matters, too. Creators expect accurate payouts, and governments expect reporting. Use tools that handle multi-country tax rules or integrate with services that do.
Privacy is another major trust factor. Set up secure hosting. Add masked payment systems to protect fan identities. Give creators the option to remain anonymous on payment records. These steps aren’t just for peace of mind — they directly affect signups and retention.
Now, let’s talk payouts. Adult sites get rejected by major processors all the time. Even if you’re fully legal, banks and services like PayPal might blacklist you. You need crypto-friendly gateways or merchant services that support high-risk industries.
Choose processors with clear adult industry terms. Build crypto options in from the start. Give users choices — and make sure creators get paid on time, every time.
⚖️ Clone Scripts vs. Scrile Connect
| Feature | Clone Scripts | Scrile Connect (Custom Build) |
|---|
| Ownership | No — tied to vendor’s code, branding limits | Yes — full backend control & white-label branding |
| Scalability | Struggle with high traffic, lag under load | Built to scale for thousands of users & streams |
| Monetization | Basic (subscriptions, tips) | Advanced: PPV, live streaming, pay-per-minute, NFTs, affiliate tools |
| Security & Compliance | Weak moderation & limited KYC/age checks | End-to-end: ID verification, anti-piracy, 2257 compliance |
| Payments | Risk of processor bans, few gateway options | Adult-friendly gateways + crypto integration |
| Customization | Limited templates, difficult to expand | 100% custom UI/UX, features matched to your niche |
| Long-Term Value | Short-term launch, frequent rebuilds needed | Future-proof, fully owned business asset |
Scrile Connect: Build a Clone That’s Yours

If you want to build a real OnlyFans clone — not just rent someone else’s script — Scrile Connect is the smart way in. It’s not a boxed product or a no-code app builder. It’s a development service tailored to your needs, goals, and audience — especially if you’re entering the adult industry.
Content entrepreneurs have been warning about this for years. If all your revenue depends on someone else’s product decisions, policies, or fragile script, your “business” can disappear the moment that foundation shifts.
“Do Not Build Your Content House on Rented Land.”
— Joe Pulizzi, “Find Your People, Sharpen Your Edge: Why Community + Tilt = Real Momentum”
A custom OnlyFans clone built with Scrile Connect follows the opposite logic. Instead of renting a brittle, generic script, you’re investing in a platform that you fully own, control, and can evolve with your creators and audience over time.
With Scrile Connect, you’re not bound by someone else’s branding or limited feature set. You launch under your own name, with full backend control and a frontend that looks and behaves exactly how you want. This is your site, your rules, your business.
Here’s what Scrile Connect delivers:
- Fully custom builds — not templates, but feature-rich websites crafted from scratch based on your requirements.
- Subscription systems — tiered plans, paywalls, free trials, and more, baked into your content flow.
- Built-in monetization — tipping, pay-per-minute streaming, pay-to-unlock content, and direct fan support.
- Live chat and private sessions — creator-fan engagement tools that go far beyond static feeds.
- Adult-ready infrastructure — hosting, streaming, and payment systems designed to withstand the strict policies of mainstream processors and platforms.
- End-to-end security — compliance, verification, and privacy tools for both creators and users.
- Advanced analytics — performance dashboards that show exactly what’s converting, trending, and making money.
With Scrile Connect, there are no forced revenue splits. No “Powered by” footers. No silent policy changes that break your business. What you build is yours — scalable, secure, and free from platform risk.
If you’re serious about launching an OnlyFans clone that you actually own, Scrile Connect is how you do it.
Conclusion
The creator economy keeps expanding — and fans aren’t just watching, they’re paying. Subscriptions, tips, unlockables, NFTs — these aren’t trends, they’re income streams. And yet, the platforms raking in billions? They’re rarely owned by the people creating the value.
There’s still space for new names. Not generic, overcrowded copies — but sharp, niche-focused, creator-owned platforms. Whether you’re building for fitness models, adult creators, cosplayers, or domme educators — a well-executed OnlyFans clone can become a serious business.
But if you want to actually earn — and scale — a $50 clone script won’t cut it. You need performance, stability, and something built to last.
That’s where custom development wins. When you own the site, you own the experience. You’re not stuck with a third-party roadmap. You’re free to monetize how you want — and pivot when the market shifts.
Contact the Scrile Connect team today and start building your own branded platform. No templates. No gatekeepers. Just a product that reflects your goals — and makes your revenue yours.
The next big name in the adult creator space isn’t another platform. It’s yours.
FAQ
What is an OnlyFans clone?
An OnlyFans clone is a custom-built site that works like OnlyFans — subscriptions, pay-per-view, tips, private messages — but it’s fully under your control. You run the brand, keep the profits, and set the rules.
What’s the difference between a clone script and a custom build?
A script is a cookie-cutter template. It’s fast and cheap, but limited. A custom build is made from the ground up — your design, your features, your roadmap. It scales, protects your brand, and gives you full ownership.
Can I include NFTs in my OnlyFans clone?
Absolutely. Many modern OnlyFans clones integrate with adult NFT marketplaces, letting creators mint, license, and sell digital content directly to fans. NFTs aren’t just hype — they’re another revenue stream that adds exclusivity and value.
FAQ – OnlyFans Clone Script & White-Label Platform Development
What is an OnlyFans clone, and what does “white-label” mean?
An OnlyFans clone is a platform built around the same core monetization logic: paid subscriptions, pay-per-view posts, tips, and direct messages. The goal is not to copy a UI — it’s to recreate the business model under your own brand.
White-label means you run it as your product: your domain, branding, pricing, content rules, and revenue flow. You own the audience and can evolve the platform without being tied to marketplace policies.
Do I need an OnlyFans clone script or a custom platform?
A “clone script” is usually a quick start: you get a basic feed, profiles, and simple paywalls. It’s fine for validating the idea, but scripts often limit customization and become fragile when traffic, payouts, and moderation load grows.
A custom platform is the better option when you want long-term ownership, stable performance, flexible monetization, and the ability to adapt to payment and compliance requirements as you scale.
What are the must-have features for an OnlyFans-style platform?
At minimum you need creator onboarding, profiles, subscription tiers, a content feed with paywalls, and a creator dashboard. On the buyer side, you need smooth checkout, media playback that works on mobile, and a simple way to follow and renew.
For retention and revenue, direct messages, pay-to-unlock media, post scheduling, and notifications matter more than “fancy design.” People stay when interaction is easy and paid content feels frictionless.
Which monetization features drive the most revenue?
Subscriptions are the foundation, but most platforms increase ARPU with layered monetization: PPV posts, paid DMs, tips, bundles, and limited drops. The highest spend often comes from direct interaction + locked content, not from the feed alone.
A strong strategy is to keep entry pricing simple, then offer clear upgrade paths: premium tiers, unlockable content collections, and message-based offers that feel personal rather than “spammy.”
How do payouts and revenue splits work on a creator platform?
Typically, subscribers pay the platform, then creators receive payouts after fees and a platform commission. A good system supports clear balance reporting, payout thresholds, payout schedules, refunds/chargeback logic, and downloadable statements.
If you plan to onboard many creators, payout transparency becomes a retention feature. Creators don’t just want “money eventually” — they want predictable timing and clean reporting.
What payment options should an OnlyFans clone support in 2026?
Payment stability is a core requirement. Many projects support multiple methods so the business isn’t dependent on one provider. The exact mix depends on your niche, geography, and content policy.
A practical architecture allows you to add or replace gateways without rewriting the product. This is important because payment rules can change, and you don’t want the whole platform to be hostage to one integration.
What compliance and safety tools should I plan for?
Common building blocks are age gating, creator verification, moderation workflows, reporting, and a clear takedown process. If your platform is adult-friendly, you also need guardrails to prevent illegal content and reduce platform risk.
On top of that, plan privacy controls and policy enforcement that is consistent. Weak governance is one of the fastest ways to lose user trust and payment access.
How do you prevent leaks and content piracy?
You can’t stop piracy completely, but you can reduce it and react faster. The usual baseline includes watermarking, controlled media delivery, screenshot deterrents where possible, fast reporting, and admin tools to investigate suspicious activity.
The bigger factor is response speed: creators feel protected when reports are handled quickly and the platform has clear enforcement actions, not when it promises “perfect prevention.”
How long does it take to build an OnlyFans clone?
It depends on scope. A lean MVP can be launched with the essentials (subscriptions, paywalls, creator dashboard, basic payouts). A full product takes longer once you add moderation tooling, multiple payment methods, advanced analytics, mobile apps, and live streaming.
In practice, the timeline is driven less by “coding speed” and more by payment/compliance setup, QA, and making the UX feel smooth for both creators and subscribers.
How much does an OnlyFans clone cost to build and run?
Cost has two parts: development and ongoing operations. Operations include hosting, storage, bandwidth (especially for video), payment fees, moderation, and support. Cheap scripts often look affordable until you hit scalability or payment issues and need a rebuild.
The clean way to estimate is to map your monetization plan, expected traffic, and media volume. A platform with heavy video and live features requires a very different infrastructure budget than a simple subscription feed.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

by Polina Yan
A consultant without a strong online presence in 2026 might as well be invisible. Potential clients don’t flip through directories anymore—they type a name or a service into a search bar, click, and make judgments in seconds. The best consulting websites are built with this reality in mind. They don’t only inform, they convince.
What counts as consulting today is broader than ever. Finance advisors and IT specialists share space with nutrition coaches, HR mentors, branding experts, and even adult industry consultants who guide creators and entrepreneurs on strategy, compliance, and monetization. All of them need a site that reflects credibility, clarity, and personality.
A great consulting website doesn’t shout; it guides. It makes it easy to understand who you are, what you offer, and how to take the next step—whether that’s booking a session, joining a newsletter, or exploring case studies. The design, the copy, and the tools behind the scenes all shape the impression a visitor takes away.
In this article we’ll explore standout consulting sites, break down the design choices that make them effective, and show how you can apply those same principles to your own project.
Why Website Design Matters for Consultants

Think about the last time you searched for a professional online. You probably clicked, looked around for a few seconds, and made up your mind fast. That’s exactly how people judge consultants. A site that feels clumsy or vague sends them away. A site that feels clear and trustworthy? That’s when they stay.
For many solo consultants, the website isn’t just decoration—it’s the business itself. A wellness coach might sell sessions directly through it. An HR consultant could use it as a calendar for bookings. Someone in the adult industry might rely on it to show they’re professional, safe, and easy to reach. In all these cases, the website is part storefront, part résumé, part handshake.
The best websites for consultants all have one thing in common: they lower the barrier between curiosity and action. That doesn’t mean flashy graphics or endless text. It means a design that answers the unspoken questions a visitor always has: “Can I trust this person? Do they know their stuff? How do I talk to them?”
For consulting, coaching, and expert services, this isn’t just about “looking good.” In trust-heavy fields, your website is the first serious proof that you’re worth listening to. As one digital agency working with professional services firms puts it in a recent insight on online credibility from Itineris:
“Reputation is built on credibility, and today, credibility begins online.”
— Harry Hammett, Itineris
That’s exactly what the best consulting websites do: they turn a few seconds of browsing into a clear signal that you’re competent, serious, and ready to solve real problems.
Key Client Expectations in Consulting Websites
Here’s what clients actually notice when they land on a page:
- The site loads quickly, and it looks good on a phone.
- There’s a small lock icon in the browser—proof the connection is secure.
- Real names, faces, or testimonials show up instead of vague promises.
- There’s a button that makes it obvious how to book, call, or send a message.
None of this is glamorous, but it works. When those basics are missing, visitors feel uneasy. When they’re in place, the site fades into the background and lets the consultant’s expertise take the spotlight.
Characteristics of the Best Consulting Websites

When you start browsing consulting sites, patterns emerge. The ones that leave a strong impression usually feel personal without losing professionalism. A clean logo, a color palette that doesn’t fight with the content, and photos that actually look like the real person behind the business—these small touches make it easier to trust what’s being offered. Visitors want to see a face and a story, not just stock images and vague promises.
Another defining trait is clarity right at the top of the page. The strongest sites don’t bury their pitch halfway down. Instead, they put their value proposition “above the fold,” where anyone arriving can immediately understand the service. Think of a single line that answers: Who are you, and why should someone listen? That opening moment sets the stage for everything else.
Good design isn’t just about looking sharp—it’s about helping visitors act. Booking calendars that sync with popular tools, quick chat options, and secure payment buttons all add momentum. When a potential client feels the site guiding them step by step, the barrier between interest and commitment gets thinner.
Design choices aren’t just aesthetics; they quietly decide whether visitors see you as credible or forgettable. Recent research summarized by Midas Touch Infotech shows just how much people lean on design when judging a business.
“68% of users are judging your business based on your web design.”
— Midas Touch Infotech
When you pair that statistic with clear copy and strong calls to action, it becomes obvious why polished consulting websites outperform generic templates: they look trustworthy and make the next step effortless.
Features That Convert Visitors into Clients
Look through real consulting website examples and you’ll notice a consistent toolkit:
- Interactive elements: calculators to estimate costs, short quizzes to define a problem, or downloadable guides that prove expertise before money changes hands.
- Evidence of results: clear portfolios, project snapshots, or client success stories that don’t read like fluff but show measurable impact.
- Calls to action in the right places: instead of dumping one big “Contact me” button at the bottom, smart sites sprinkle actions where they make sense—after a case study, beside a testimonial, or within a pricing section.
- Transparency in services and pricing: not always a detailed list of numbers, but at least enough to let visitors gauge if they’re in the right ballpark.
- Accessibility across devices: not a flashy feature, but critical. If the site lags on a phone, clients won’t wait.
Together, these elements form a rhythm: credibility first, action second. The websites that master this rhythm are the ones people remember—and more importantly, the ones people contact.
That “evidence of results” is what turns a nice-looking site into a convincing one. Agencies that specialize in consulting websites consistently point to social proof—testimonials, case studies, client logos—as the strongest trust lever you can pull. As Knapsack Creative notes in their guide on consulting website social proof:
“The most powerful way to build that trust online is through social proof.”
— Knapsack Creative
This matches what you see in the best consulting websites you analyze: they don’t just say they get results—they show real clients, real outcomes, and let that proof do the heavy lifting.
Best Consulting Website Examples in 2026
Learning design principles on paper is helpful, but watching them in action in actual sites makes the lessons more memorable. The best consulting websites have in common just a few characteristics—a clear brand, compelling text, and features that push people forward toward action. Large companies employ such strategies in order to leverage their influence, and small players use them in order to hold ground against crowded spaces. Below are our top 5 consulting websites to study in 2026 (plus a few independent consultant website examples). Each one shows a different way to build trust fast: authority content, case-study storytelling, clear positioning, and a frictionless “book a call” path.
Top 5 Consulting Websites (Quick List)
1) McKinsey & Company — authority + insights hub
2) Boston Consulting Group (BCG) — visual storytelling + interactive case studies
3) Bain & Company — guided narrative + warm brand tone
4) Accenture — technology consulting website with heavy case-study depth
5) GrowthLab — personal brand funnel done right
McKinsey & Company
McKinsey’s website is a masterclass in authority-building. It isn’t flashy; instead, it feels like an encyclopedia of insights, filled with research reports, interactive graphics, and trend analysis. The homepage greets you with bold statements supported by numbers, while the navigation leads to deep dives on industries, case studies, and global issues.
Key Features:
- Data-driven articles and reports published regularly.
- Clear industry segmentation, making it easy for visitors to find their sector.
- Minimalist design that highlights content over decoration.
- Consistent calls to action encouraging readers to explore or subscribe.
Takeaway:
By focusing on knowledge-sharing, McKinsey builds trust long before a potential client even considers reaching out. Visitors come for insights and leave with the sense that this firm has the resources to solve large-scale problems.
Boston Consulting Group (BCG)
BCG’s site leans into visual storytelling. The homepage immediately feels dynamic, with bold typography and interactive features that highlight their focus on transformation and innovation. Scrolling through, you’ll encounter case studies packaged almost like short documentaries, balancing sharp design with digestible information.
Key Features:
- Strong visual identity reinforced through photography and motion design.
- Case studies presented with interactive graphics.
- Content grouped by themes such as sustainability, digital, or leadership.
- Prominent links to global insights and reports.
Takeaway:
BCG proves that a corporate consulting site doesn’t have to be dry. Their design choices make complex business transformation stories accessible and engaging, showing how visual presentation can turn information into inspiration.
GrowthLab by Ramit Sethi

GrowthLab isn’t a corporate giant—it’s built around Ramit Sethi’s personal brand, and that’s exactly what makes it powerful. The site feels like a conversation rather than a lecture. Bold headlines, direct copy, and clear funnels guide visitors into signing up for courses or newsletters. Every element reflects the idea that trust is earned by being upfront and personable.
Key Features:
- Prominent personal branding with photos and direct messaging.
- Lead magnets like free guides and email courses.
- Simple layouts that push attention toward calls to action.
- Stories and testimonials that emphasize transformation.
Takeaway:
GrowthLab shows how personality and expertise can carry a consulting business online. Independent consultants can study this approach and see how personal branding paired with lead capture tools creates a steady pipeline of clients.
Lisa Richey, Business Etiquette Consultant

Lisa Richey’s site is an excellent demonstration of how niche consultants can shine. The site is friendly, clear, and rooted in her specialization—etiquette instruction. The homepage introduces the visitor at once as an accessible expert, and the navigation centers on in-use services such as workshops and training programs.
Key Features:
- Clear description of services with easy booking options.
- Testimonials from clients to reinforce credibility.
- Personal photos that highlight trustworthiness and relatability.
- A simple but polished design that keeps focus on the message.
Takeaway:
Her site proves that the best independent consultant websites aren’t necessarily in need of vast contents databases. A solid niche specialization, supplemented with trust indicators and friendly design, is enough to give one consultant the same sense of credibility as that of a bigger company.
Erika Heald Consulting
Erika Heald’s site is built around clarity. Instead of overwhelming visitors with jargon, the copy focuses on what she actually does—content strategy, community building, and consulting for businesses that want a sharper voice online. The layout is straightforward, but the simplicity works in her favor.
Key Features:
- Direct messaging that avoids buzzwords.
- Easy navigation that highlights core services.
- Blog posts and resources that display expertise.
- Clear contact paths that invite quick outreach.
Takeaway:
Erika’s website proves that consultants don’t need complexity to stand out. By putting services front and center, and avoiding distractions, she creates a frictionless experience that inspires confidence in potential clients.
Accenture (Technology / IT Consulting Website)
Accenture’s website is a strong benchmark for technology consulting websites because it balances scale with clarity. It offers deep navigation by industries and services, but still keeps “proof” close to the surface: case studies, client stories, and practical insights that signal execution — not just strategy.
Key Features:
– Strong case-study structure (easy to scan, easy to trust)
– Clear segmentation by industry and capability
– High-volume content without losing navigation clarity
– Multiple conversion paths (contact, insights subscriptions, events)
Takeaway:
For IT consulting websites, depth works only when it’s organized. Accenture shows how to publish a lot and still feel structured and credible.
Bain & Company
Bain’s website is polished in a different way from McKinsey or BCG. It feels less like an academic resource and more like a guided journey. Each section is designed to lead you somewhere—whether that’s a case study, an industry insight, or a service explanation. The storytelling approach draws you deeper with every scroll.
Key Features:
- Engaging homepage with client-centric stories.
- Intuitive navigation through industries and solutions.
- Consistent use of photography and design elements to add warmth.
- Calls to action woven naturally into each section.
Takeaway:
Bain shows how large firms can balance authority with accessibility. Instead of relying only on research-heavy content, they mix storytelling with clear service offerings, making the visitor feel like they’re part of the narrative.
Comparison of Key Elements Across Top Consulting Websites
| Website | Type | Standout Feature | Takeaway |
| McKinsey | Global firm | Research insights hub | Authority built through deep, data-driven content |
| BCG | Global firm | Interactive case studies | Visual storytelling makes complex topics engaging |
| GrowthLab | Independent | Lead magnets, courses | Personal brand paired with funnels drives sales |
| Lisa Richey | Niche | Service clarity, testimonials | Focus and approachability build strong trust |
| Erika Heald | Independent | Simple, direct messaging | Clarity and frictionless navigation win confidence |
| Bain & Company | Global firm | Client-centric stories | Guided storytelling turns visitors into prospects |
How to Build a Consulting Website That Stands Out

There’s no shortage of ways to get a site online. A solo consultant might be tempted by DIY website builders: quick, cheap, and with plenty of templates. The problem? Those templates often look the same, and when every competitor uses the same design, you fade into the background. SaaS-based solutions offer more polish but still come with limitations—branding that isn’t truly yours, features you don’t control, and subscription fees that pile up. Larger firms usually move toward custom-built solutions because they need security, scalability, and full ownership. That’s the difference between a site that blends in and one that competes with the best consulting websites.
If you want to build a consulting website that carries weight, start by planning beyond aesthetics. Design matters, but so does the flow: how someone books you, how payments are handled, and how you prove you’re worth hiring.
Practical Steps to Start Today
- Define your niche and audience – Know exactly who you want to reach and tailor your message for them.
- Choose your monetization model – Will you charge hourly, offer packaged services, or build a subscription plan?
- Prioritize branding and payments – Your logo, color scheme, and story should be consistent, while payment options need to be seamless and secure.
- Add engagement tools – Booking calendars, live chat, or gated content help turn casual visitors into paying clients.
Developing online presence is more than that initial setup—it’s iterative. The finest consulting sites grow along with the consultant, tightening up as services expand or audiences shift. What distinguishes the finest aren’t templates—it’s the judicious combination of personal branding, trust markers, and working tools that streamline business both ends.
Scrile Meet: Customizable Development for Consulting Websites
Most consultants outgrow generic templates quickly. You might start with a drag-and-drop builder, but as soon as you need secure payments, branded video sessions, or scalable tech, the cracks show. Scrile Meet fills that gap. It’s not a pre-made platform—it’s a development service that adapts to your goals, giving you the flexibility to create a consulting site that holds its own among the best consulting websites.
With years of experience across varied industries—from corporate advisory firms to adult coaching—Scrile Meet understands how consultants shape and grow their online presence. The service combines this experience with a toolkit built to support consultants who want more than surface-level design.
Key benefits include:
- Full white-label branding that puts your name, not someone else’s, front and center.
- Live video consultation features, covering both one-on-one and group sessions.
- Integrated payment systems with direct payouts for smooth transactions.
- Flexible monetization models, from subscriptions and pay-per-minute billing to premium content.
- Scalable, low-latency technology (WebRTC/RTMP) that ensures calls and streams feel seamless.
Behind these features sits a support system—project managers, custom developers, and 24/7 hosting—that ensures the site isn’t just launched but actively maintained. For consultants, that means the freedom to shape a site around your practice rather than squeezing your practice into a rigid template.
Scrile Meet positions itself as a long-term partner, making sure your consulting website can evolve alongside your business.
Conclusion
The best consulting websites all follow the same thread: they make services clear, build trust with proof, and rely on technology that makes the client’s next step effortless. From global names like McKinsey to niche professionals running solo practices, the examples show that size doesn’t matter—clarity and function do. If you’re ready to take your consulting business online or improve what you already have, the next step is simple. Define your goals, think about how you want to engage clients, and contact the Scrile Meet team today to discuss a site built exactly around your needs.
FAQ – Best Consulting Websites (Design, Trust, Booking, Conversion)
The answers people search after they browse consulting website examples: what actually converts, what to show first, and how to turn interest into booked calls.
What makes a consulting website “the best” in 2026?
▾
The best consulting websites do three things fast: they explain what you help with, prove you’re credible, and make the next step obvious (book, message, or explore results).
“Best” is not about fancy animations. It’s about clarity, trust markers, and a frictionless path from curiosity to action—especially on mobile.
What should be “above the fold” on a consulting homepage?
▾
A single, specific promise: who you help + what outcome you deliver. Then one primary call to action (Book a call / Request consultation / See case studies).
If a visitor can’t answer “What do you do?” in 5–10 seconds, they’ll bounce—even if your work is excellent.
What trust elements convert visitors into clients?
▾
The strongest trust stack is simple: a real face + real story, client outcomes (case studies), and social proof (testimonials, logos, reviews) that feels specific rather than generic.
Even one strong case study with numbers beats ten paragraphs of “we deliver value.” Proof removes doubt faster than copy.
Should I show pricing on my consulting website?
▾
You don’t have to publish exact numbers, but you should reduce uncertainty. Many high-performing consulting sites use ranges, package tiers, “starting at” pricing, or clear descriptions of what’s included.
Pricing transparency filters out poor-fit leads and makes good-fit leads more confident when they hit the booking page.
What’s the best booking flow for consulting websites?
▾
The best flow feels like a single path: pick a service → pick a time → pay (optional) → get confirmation + next steps. Every extra click increases drop-offs.
If you want higher-quality calls, add a short intake form before confirmation. Keep it focused: goals, timeline, budget range, and the one key problem to solve.
Are blog posts and “insights hubs” worth it for consultants?
▾
Yes—when you treat content as authority, not filler. One strong article that answers a real client question can bring leads for months and makes your expertise visible before the first call.
The best content strategy is “proof content”: frameworks, examples, common mistakes, and mini case studies that show how you think.
What interactive elements help consulting sites convert better?
▾
The best interactive elements reduce uncertainty: short quizzes, cost calculators, readiness checklists, and downloadable guides that make your value tangible.
Think of them as “micro-wins.” A visitor gets clarity first, then feels comfortable booking.
What are the biggest mistakes on consulting websites?
▾
The classic mistakes: vague positioning (“we help businesses grow”), too many CTAs fighting each other, and no real proof (no outcomes, no testimonials, no clear process).
On the technical side: slow mobile performance, confusing navigation, and forms that feel unsafe or outdated. Trust breaks fast when the experience feels clumsy.
Can consulting websites work for non-traditional niches (creator economy, adult industry, etc.)?
▾
Yes—and in those niches, trust signals matter even more. Clear service boundaries, transparent policies, and professional presentation help clients feel safe booking you.
The goal is the same: credibility + clarity + a simple booking flow. The difference is you may need stronger compliance messaging and carefully chosen payment/communication tools.
Template site vs custom build: when should a consultant go custom?
▾
Templates are fine for early validation. Go custom when your website becomes your product engine: branded client portal, integrated booking + payments, gated content, multi-service packages, or multiple consultants under one brand.
Custom also makes sense when you want full control over data, UX, and roadmap—so your business doesn’t depend on a platform’s limits.
Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.

