

Voice recognition is no longer a future technology but now a mainstream tool in everything from healthcare and customer service to smart assistants and accessibility and automation systems. It is becoming part of everything from apps and messaging to virtual personal assistants and smart devices in the home.
One of the prime movers towards accomplishing this revolution is the swift evolution in artificial intelligence (AI) and natural language processing (NLP). Speech recognition Python-based solutions fueled by AI have evolved immensely in precision to enable real-time transcriptions, voice command recognition, and multilingual recognition.These technologies are making interactions faster and more efficient, whether it’s for virtual assistants like Siri and Alexa, medical transcription services, or automated customer support systems.
Why Python Speech Recognition?
Among the many programming languages used for voice recognition, Python speech recognition stands out as the top choice for developers. Python’s ecosystem offers several powerful libraries that allow developers to integrate speech-to-text functionalities into applications with minimal effort. Its extensive open-source community and machine learning frameworks make it the go-to language for AI-driven projects.
Here’s why Python is widely used for speech recognition:
- Rich library support – Python offers multiple dedicated speech recognition libraries, such as SpeechRecognition, DeepSpeech, and Vosk, that simplify the integration process.
- Ease and usability – Its programming syntax readability allows one to develop complex voice-based AI systems with much ease and flexibility in use
- Robust machine learning and AI features – Python has direct integration with machine learning and deep learning platforms like TensorFlow and PyTorch to enable organizations to construct highly precise, custom-built speech recognition models.
- Cross-platform compatibility – Such systems work across multiple operating systems, ensuring scalability for web, mobile, and embedded applications.
How Speech Recognition Works in Python
Speech recognition enables machines to understand and process spoken language, converting it into readable text or commands. The tech can also provide voice assistants, in-home devices, automated transcription tools, and voice-free systems. Such systems can be developed in a less complicated way through developments in Python speech recognition and with the aid of sophisticated AI-based tools.
Human speech recognition includes both linguistic processing and machine learning models being used correctly in a very complicated process.
At its core, speech recognition isn’t magic — it’s about turning complex sound patterns into understandable language using advanced models. Modern systems often rely on neural networks and deep learning to improve accuracy far beyond simple dictionary matching.
“Whisper is a machine learning model for speech recognition… capable of transcribing speech in English and several other languages, and… improved recognition of accents, background noise and jargon compared to previous approaches.”
— OpenAI on Whisper (speech recognition system), Wikipedia
That’s why libraries like Whisper, DeepSpeech, and Vosk form the backbone of Python speech projects — they leverage modern machine learning architectures to decode human speech in ways older systems could not.
Key Components of Speech Recognition Python Applications
- Acoustic Modeling. Speech consists of phonemes, which are the fundamental units of sound. The AI systems identify these sounds and match them to their corresponding letters or syllables. Acoustic models enable the recognition of words that sound alike and handle the variations in pronunciation.
- Language modeling. The system then has to organize words and sentences in a coherent order after sensing phonemes. Prediction models enhance recognition by predicting words that most likely follow in a sentence in largely the same manner that autocorrect or predictive input works in cell phones.
- Noise Filtering & Audio Processing. Recognition of speech is not only about recognizing words—participating words must be filtered from ambient noise and sound. Most speech recognition Python libraries come with noise cancellation to enhance the performance in real scenarios, i.e., in the office, in a crowd, or in the context of in-car free hand conditions.
Neural Network Processing. They have the latest speech recognition systems using AI and deep models to improve accuracy levels. Advanced deep models and AI assist the systems in identifying patterns in enormous amounts of spoken data to adapt to accents and dialects and patterns changing with time.
Top Python Speech Recognition Libraries in 2026
Python offers a variety of powerful speech recognition libraries, each suited for different use cases. Whether you need a lightweight API-based tool, an offline speech recognition system, or an advanced deep learning model, there’s a solution available. Below is a comparison of the five best speech recognition Python tools in 2026, covering their strengths, weaknesses, and ideal use cases.
Comparison of Top Python Speech Recognition Libraries
| Library | Type | Strengths | Weaknesses | Best For |
|---|---|---|---|---|
| SpeechRecognition | Wrapper for multiple APIs | Easy to use, lightweight, flexible, supports Google/IBM/Microsoft | Internet dependent, weak offline support | Quick integration, basic transcription |
| Mozilla DeepSpeech | Offline, open-source, TensorFlow-based | High accuracy, customizable, privacy-friendly | Needs GPU/high CPU, large models | Privacy-sensitive apps, custom AI |
| Vosk | Offline, lightweight | Low latency, multilingual, works on embedded devices | Limited pre-trained models, requires tuning | IoT, Raspberry Pi, smart devices |
| Google Speech-to-Text API | Cloud-based | Very accurate, real-time streaming, auto-punctuation | Subscription costs, needs internet, latency risk | Enterprises, live transcription, call centers |
| OpenAI Whisper | AI-powered, multilingual | Extremely high accuracy, understands accents & noise, context-aware | Heavy resource use, slower on low hardware | Journalism, podcasts, multilingual assistants |
SpeechRecognition
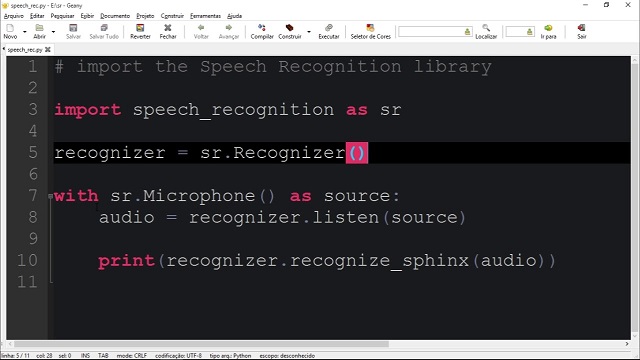
SpeechRecognition is one of the most widely used Python libraries for speech-to-text conversion. It acts as a wrapper for multiple speech recognition engines, making it easy to integrate with cloud-based and offline services. The library supports APIs like Google Web Speech, CMU Sphinx, IBM Speech to Text, Wit.ai, and Microsoft Azure Speech.
Strengths:
- Easy to implement – Requires minimal setup and works with a simple API call.
- Lightweight – Does not require extensive computational power.
- Flexible – Supports multiple speech engines, allowing developers to choose the best fit.
Weaknesses:
- Internet dependency – Most of its features rely on cloud APIs, requiring an internet connection.
- Limited offline capabilities – The CMU Sphinx engine is available for offline use but lacks accuracy compared to deep learning-based alternatives.
Best Use Cases:
- Quick speech recognition integration into Python applications.
- Developers looking for a simple API to access Google or IBM speech services.
- Basic transcription needs where internet access is available.
Mozilla DeepSpeech
Mozilla DeepSpeech is a deep learning-based, open-source speech recognition system built on TensorFlow. It is trained on thousands of hours of voice data and offers high accuracy, even in challenging conditions. Unlike cloud-based solutions, DeepSpeech runs entirely offline, making it suitable for privacy-sensitive applications.
Strengths:
- Fully offline processing – No internet connection required.
- High accuracy with proper training – Can be fine-tuned with custom voice data.
- Open-source flexibility – Developers can modify and improve models based on their needs.
Weaknesses:
- Requires high computational power – Best suited for systems with GPUs or high-end CPUs.
- Large model size – Can be resource-intensive compared to lightweight libraries like SpeechRecognition.
Best Use Cases:
- Privacy-focused applications that require offline speech recognition.
- AI-driven applications needing accurate speech-to-text conversion.
- Developers looking to fine-tune a speech model for a specific use case.
Vosk
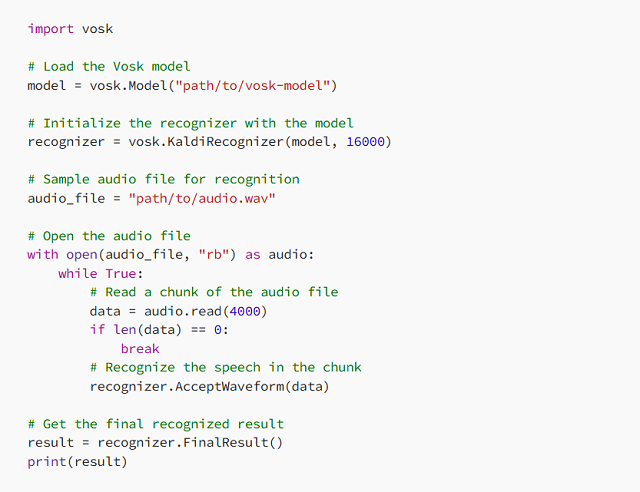
Vosk is a lightweight, offline speech recognition Python library designed for low-power devices like Raspberry Pi and embedded systems. It supports multiple languages and provides real-time speech processing with minimal resource consumption.
Strengths:
- No internet dependency – Works completely offline.
- Low latency – Optimized for real-time applications.
- Multilingual support – Recognizes speech in over 20 languages.
Weaknesses:
- Fewer pre-trained models compared to cloud-based APIs.
- Requires additional tuning to improve accuracy for niche applications.
Best Use Cases:
- Embedded systems (Raspberry Pi, IoT applications, smart home devices).
- Developers needing offline speech recognition with minimal hardware requirements.
- Multilingual speech processing for global applications.
Google Speech-to-Text API
Google Speech-to-Text API is a cloud-based speech recognition service that provides highly accurate transcription using Google’s deep learning models. It supports real-time and batch processing, making it suitable for applications requiring fast and scalable speech recognition.
Strengths:
- High accuracy across multiple languages.
- Supports real-time streaming for live applications.
- Includes auto-punctuation and noise cancellation features.
Weaknesses:
- Requires a Google Cloud subscription, which can be expensive for high-volume applications.
- Latency issues may arise in environments with poor internet connectivity.
Best Use Cases:
- Large-scale enterprise applications needing cloud-based transcription.
- Call centers and customer support automation.
- Live streaming applications requiring real-time speech-to-text conversion.
OpenAI Whisper
OpenAI Whisper is an AI-powered speech recognition Python model trained on a massive dataset of multilingual speech. It is designed for high-accuracy transcription, multi-language support, and natural conversation understanding.
Strengths:
- Extremely high accuracy, even with accents and noisy backgrounds.
- Supports multiple languages, making it ideal for global applications.
- AI-driven transcription with improved contextual understanding.
Weaknesses:
- Requires significant processing power for real-time applications.
- Can be resource-intensive compared to lightweight libraries.
Best Use Cases:
- High-accuracy transcription services for podcasts, interviews, and journalism.
- AI-driven voice assistants with multilingual capabilities.
- Businesses needing contextual understanding beyond simple speech-to-text conversion.
Python continues to be a leading choice for developing speech recognition applications due to its extensive library support. Whether you need a simple API-based tool like SpeechRecognition, an offline solution like Vosk, or an advanced AI-powered model like OpenAI Whisper, there is a Python speech recognition library suited for your project.
Choosing between open‑source libraries and cloud‑based speech APIs isn’t just a technical decision — it’s a strategic one. The tradeoffs often come down to control versus convenience.
“Open-source solutions… offer the flexibility to modify the code to meet specific requirements. However, open-source solutions… must be provided and managed by you… Additionally, the accuracy of open-source tools is often inferior to that of cloud-based alternatives…”
— AssemblyAI, “Python Speech Recognition in 2025”
This highlights why many developers start with an API like Google Speech or AssemblyAI for accuracy and then graduate to local, customized systems when they need more control, privacy, or offline capability.
How to Implement Python Speech Recognition in Your Project
Python speech recognition systems have made changing the way that companies automate processes, communicate with users, and process voice data a reality. From virtual assistant-based systems powered by artificial intelligence to voice command and real-time transcription and voice-controlled smart devices, application utilization of speech recognition must be weighed and optimized.
To successfully implement Python speech recognition technology, firms have to select the right library, calibrate processing to realworld specifications and integrate the tool into the process. High accuracy cloud-based APIs are required in some applications while independent and offline models work in others
The secret to an effective speech recognition Python project is finding the ideal balance between accuracy and speed and being in a position to connect well with other systems.
Setting Up a Python Speech Recognition System
Before diving into implementation, it’s important to define what the speech recognition system will be used for. A real-time transcription service requires high-speed processing, whereas an AI chatbot might need natural language understanding in addition to voice-to-text conversion.
Once the use case is clear, the next step is setting up the development environment. This involves installing the necessary Python libraries and configuring the system for optimal performance.
Cloud-Based vs. Offline Speech Recognition
One of the first decisions businesses face when implementing Python speech recognition is whether to use cloud-based or offline speech processing.
Cloud-based services, such as Google Speech-to-Text or OpenAI Whisper, provide high accuracy and continuous improvements because they leverage deep learning models trained on massive datasets. These services are ideal for applications that require real-time, multilingual speech recognition. However, they depend on an internet connection and often come with ongoing usage costs.
Offline models, like DeepSpeech and Vosk, process voice data directly on the device, making them a great choice for privacy-sensitive applications where data security is a concern. These solutions allow businesses to avoid external API costs, but they may require fine-tuning and additional computational resources for training and optimization.
For businesses operating in high-security industries, such as healthcare, finance, and legal services, offline models provide greater control over voice data without relying on third-party providers.
Optimizing Speech Recognition for Accuracy and Performance
The speech recognition model is as good as the quality input it gets. Even the most advanced AI-based systems fail to handle poor quality audio, high levels of background noise, or heavy accents. To have a better recognition percentage, companies need to work on sound optimization and model adjustment from the AI end
Major factors affecting accuracy in speech recognition:
- Audio Quality – High-quality microphones and noise elimination methods enhance speech audibility and produce better transcription accuracy.
- Background noise management – Using sound filtration and noise cancellation techniques enables speech models to tune in to the voice of the speaker
- Speaker Adaptation – Training models to recognize multiple accents and speaking patterns ensures higher accuracy to multiple clusters of users
- Word Choice Within Domain – Training models to a domain-specific lexicon increases awareness to business-specific usage
For multiple language applications, multiple language support will be required. There exist Python speech recognition libraries that natively support multiple languages and those that allow multiple language support through changing between multiple models trained in different languages. Business organizations that have international scope should prefer solutions with robust language processing
Integrating Speech Recognition into Business Applications
Speech recognition technology is now being widely adopted across various industries, providing businesses with new opportunities for automation and customer interaction. The implementation of this technology depends on the specific use case and industry requirements.
depends on the specific use case and industry requirements.
Real-World Business Applications of Python Speech Recognition:
- AI-powered Customer Service – Virtual and AI-powered chatbots utilize speech recognition to comprehend the inquiries of the customers and respond automatically.
- Medical Transcription Services – Physicians would not be depending on speech-to-text systems to auto-document along with note-taking.
- Financial & Legal Transcription – It reduces paperwork in financial reports and legal cases and client conversations
- Hand-Free devices for Smart devices – Devices with IoT such as voice assistant smart home devices and voice command in vehicles use voice recognition to offer hand-free services.
- Live Captioning & Subtitling – Automatic transcription tool helps organizations produce live captions in real-time online conferences, webinars, and live streams.
Each of these use cases requires different levels of accuracy, latency, and language processing capabilities, making it essential to choose the right speech recognition Python solution for the job.
Ensuring Scalability and Security in Speech Recognition Applications
Scalability is a paramount concern for businesses handling vast volumes of voice data. A speech recognition system must be capable of handling thousands of interactions simultaneously without compromising speed or accuracy.
Security is also an important concern, particularly when dealing with sensitive user data. Some industries, such as finance, healthcare, and government, must comply with strict data privacy regulations like GDPR and CCPA.
To ensure compliance, businesses should consider:
- On-premises speech recognition solutions for greater control over data.
- End-to-end encryption for protecting voice interactions.
- AI bias mitigation to prevent inaccuracies based on speaker demographics.
Balancing performance, security, and cost-efficiency is essential for businesses that rely on AI-powered speech recognition for mission-critical applications.
Challenges and Limitations of Speech Recognition
While Python speech recognition has advanced significantly, real-world implementation comes with several challenges that affect accuracy, speed, and user experience. Companies implementing speech-to-text solutions need to overcome technical constraints to support fluent and seamless functioning.
Background noise is one of the biggest issues. In noisy environments like offices, public spaces, and call centers, speech recognition models struggle to distinguish the speaker’s voice from background noises, simultaneous conversations, or echoing acoustics.This leads to continuous misinterpretations, which makes the system less reliable.
Another challenge is dialect and accent recognition. While many speech recognition Python models are trained on standardized datasets, they often fail to accurately process regional accents, fast speech, or non-native pronunciations. This can result in incorrect transcriptions or repeated errors, making the system frustrating for diverse user groups.
Latency is another concern, particularly for real-time speech recognition applications. Systems requiring real-time voice-to-text transformation, such as AI chatbots or live transcription software, need to maintain processing latency as low as possible. High latency can make interactions respond slowly or become unresponsive, affecting user experience in a negative manner.
To overcome these limitations, businesses optimize their speech recognition models using noise reduction filters, AI-powered learning, and continuous model fine-tuning. By adapting speech recognition Python solutions to real-world conditions, companies can significantly improve accuracy and performance.
Scrile AI: The Best Custom Development Service for Python Speech Recognition
Businesses looking to implement speech recognition Python solutions need more than just an off-the-shelf API—they need a customized, scalable, and efficient system that seamlessly integrates with their existing workflows. Scrile AI offers a tailored approach to speech recognition development, ensuring that businesses get precisely the features, accuracy, and performance they need.
Contrary to typical cloud-based applications limiting personalization and control, Scrile AI provides fully customized speech recognition models, designed for industry-specific use. Customer service automation, medical transcription, legal documentation, or voice-based smart apps, Scrile AI provides cutting-edge AI solutions on the basis of proprietary business requirements.
Why Choose Scrile AI Over Off-the-Shelf Solutions
| Option | Ownership | Customization | Security | Scalability | Integration | Weak Points |
|---|---|---|---|---|---|---|
| Off-the-Shelf APIs (Google, IBM, etc.) | Belongs to provider | Limited, generic models | Provider-dependent compliance | Scales with cost | Easy to plug & play | Vendor lock-in, recurring fees |
| Open-Source Models (Vosk, DeepSpeech, Whisper) | Open community | High, but requires expertise | Depends on implementation | Flexible, but resource heavy | Needs dev effort | Requires AI/ML specialists |
| Scrile AI (Custom Python Development) | Full client ownership | Tailored to industry (medical, legal, finance, support) | GDPR/CCPA compliant, business-grade | Enterprise-level, low-latency, live-ready | Seamless integration into existing apps | None — handled as turnkey by Scrile |
What Scrile AI Offers
Scrile AI specializes in custom-built AI solutions, allowing businesses to leverage advanced Python speech recognition technology while maintaining complete ownership and flexibility over their systems.
- Custom speech recognition models – Tailored for specific industries to give higher accuracy in specialized vocabulary and use cases.
- Seamless integration – Integrates with existing apps, software environments, and backends without problems of compatibility.
- Scalable infrastructure – Designed to process live voice handling with high-speed transcription and low latency.
- Multilingual speech recognition – Supports multiple languages and dialects, making it ideal for global businesses.
Why Choose Scrile AI Over Off-the-Shelf Solutions?
The majority of companies begin with third-party APIs but later discover that pre-existing solutions are significantly limiting. Scrile AI escapes vendor lock-in and platform limitations and offers:
- End-to-end bespoke AI models – No reliance on third-party, and thus companies will fully own their technology.
- Business-class security – GDPR, CCPA, and other data privacy law compliant, hence secure and safe voice data processing.
- Support and scalability – Engineered for businesses who need long-term stability, upkeep, and nurturing for mass scale operations.
For businesses serious about building powerful, AI-driven voice solutions, Scrile AI provides the best Python speech recognition development service available. Explore Scrile AI’s custom AI solutions today and bring advanced speech recognition capabilities to your business.
Conclusion
The landscape of Python speech recognition is evolving rapidly, with numerous libraries that offer advanced features for real-time transcriptions, AI assistants, and voice automation. The choice of the appropriate tool depends on your needs, levels of accuracy, and scalability objectives.
For businesses that require custom solutions, relying on pre-built APIs may not be enough. Scrile AI provides tailored AI development, ensuring full control, security, and seamless integration into any application.
Take the next step—explore Scrile AI today and build a custom AI-powered speech recognition Python system.
FAQ – How to Create a Telegram Bot (BotFather, Bot API, AI, Monetization)
Answers to the questions people ask after they launch their first bot: setup, hosting, rate limits, payments, and adding AI.
How do I create a Telegram bot with BotFather?
Open Telegram, find @BotFather, and use /newbot. You’ll set a display name, pick a username ending in “bot,” and receive an API token.
Treat the token like a password. Store it in environment variables (not in public repos), rotate it if it leaks, and never paste it into screenshots or tutorials.
Webhook vs long polling: which one should I choose?
Webhook is the production-friendly option: Telegram pushes updates to your server instantly, which improves responsiveness and reduces wasted requests.
Long polling is great for prototypes because it’s simple, but you still need to handle retries, timeouts, and process restarts. If you’re building something serious, plan to move to webhooks.
What stack is best for Telegram bots in 2026?
For most teams, Python or Node.js wins because libraries are mature and deployment is straightforward. In Python, aiogram (async) and python-telegram-bot are popular. In Node.js, many teams use Telegraf or grammY.
Choose based on your product, not hype: async support, webhook handling, middleware, and how easily you can integrate databases, payments, and analytics.
Where do I track Telegram Bot API updates?
The safest habit is to check the official Bot API documentation’s “Recent changes” section before big releases or feature launches.
If you want updates in real time, follow Telegram’s bot-focused channels (news + discussion) so you catch UX-breaking changes early, not after your users report bugs.
How do I handle rate limits, flood control, and 429 errors?
Don’t brute-force retries. When Telegram returns flood control, it often includes a retry_after value. Respect it, wait, then retry.
In production, you’ll want an outgoing message queue that smooths bursts (especially broadcasts). Treat rate limits as a product constraint: design flows that don’t spam users or hammer the API.
Is the Telegram Bot API free, and what are “paid broadcasts”?
The Bot API itself is free to use, but broadcasting has practical limits. For large newsletter-style sends, Telegram introduced Paid Broadcasts, which can raise throughput when you pay per message using Telegram Stars.
This matters for architecture: if your business depends on mass sends, budget for it (or design batching/segmentation that fits the free limits).
Can I monetize a Telegram bot?
Yes—Telegram bots are often monetized through subscriptions, paid access to channels, one-time purchases, lead-gen funnels, and donations. The bot becomes the “checkout + delivery” layer right inside the chat.
The important part is consistency: access rules, renewals, user states, and support flows must be automated. A monetized bot fails when payments work, but delivery and permissions are managed manually.
How do I add AI (ChatGPT-like) features to a Telegram bot?
AI bots are usually a combination of Telegram messaging + your AI backend. Your bot receives updates, sends user text to an LLM endpoint, then streams back a clean answer (often with typing indicators and short chunks).
To make it feel “human,” keep context per user, add safe fallbacks, and control costs with message limits, caching, and smart prompt design. AI isn’t just the model—it’s the whole product loop.
How do I keep my Telegram bot secure?
Start with basics: protect the token, validate webhook requests, and avoid logging sensitive user content. If you store user data, keep it minimal and encrypt secrets.
Security is also operational: monitor for spikes, lock down admin commands, and separate “public bot logic” from internal tools. The fastest way to lose trust is a bot that leaks tokens or mishandles payments.
When should I build a custom bot instead of using a no-code builder?
No-code is perfect for testing an idea. Custom development becomes worth it when the bot is core to your business: you need full branding, deeper integrations, higher performance, custom monetization, or strict control over data and UX.
If your bot needs to scale beyond “a helpful helper” into a product, a custom architecture (queues, analytics, payments, admin tools) saves you from platform limits later.

Polina Yan is a Technical Writer and Product Marketing Manager, specializing in helping creators launch personalized content monetization platforms. With over five years of experience writing and promoting content, Polina covers topics such as content monetization, social media strategies, digital marketing, and online business in adult industry. Her work empowers online entrepreneurs and creators to navigate the digital world with confidence and achieve their goals.
Been experimenting with Scrile AI’s custom setup for our legal voice dictation tool. The accuracy for domain-specific vocabulary (like “affidavit” or “jurisdiction”) is really impressive.
Interesting point about cloud vs. offline recognition. I think hybrid models will dominate — using Whisper locally for privacy but falling back to cloud APIs for tricky edge cases.
Great breakdown! I switched from DeepSpeech to Whisper this year — the accuracy leap was mind-blowing. But yes, you need serious GPU power to make it run smoothly in real time.
This article perfectly sums up the state of speech recognition in 2025. I’ve been working with Vosk for a few months, and it’s amazing for offline IoT projects. Totally agree that Python is unbeatable for quick experimentation.
Fantastic read 👏 The accessibility applications of Python speech recognition deserve even more attention. Voice interfaces are changing how people with disabilities interact with tech.
The part about accent and noise issues hit home. Our startup in customer support automation still struggles with dialect-heavy speech data. Curious if Scrile AI can handle multilingual call center setups?
Loved the comparison table — it’s concise and practical. Personally, I’d add that OpenAI Whisper + custom noise filtering pipelines give incredible results for podcasts and interviews.
This is the most up-to-date article I’ve seen on Python speech recognition this year. You can really tell it’s written by someone who understands both the tech and the business side. Bookmarked!
As someone building a medical transcription app, this post was exactly what I needed! I’m glad you mentioned Scrile AI — customization and privacy are critical in healthcare, and that’s usually missing in off-the-shelf APIs.
Finally, a blog that goes beyond surface-level “Top 5 libraries”! The explanation of acoustic and language modeling was so clear. Thanks for writing in a way even junior devs can understand.